
กระแสของ Large Language Model (LLM) ช่วงปลายปี 2022 ทำให้โลกตื่นเต้นไปกับคลื่น AI รอบใหม่ แต่โฟกัสที่เรามักพูดถึงกันคือเรื่องตัวโมเดลว่าของใครก้าวหน้ากว่ากัน ชื่อที่คุ้นเคยก็อย่าง GPT (OpenAI), PaLM (Google), LLaMA (Meta), Claude (Anthropic) เป็นต้น
แต่การเกิดขึ้นของโมเดลขนาดใหญ่ลักษณะนี้ จำเป็นต้องมี “เสาหลัก” หรือปัจจัยพื้นฐานอย่างน้อย 3 ข้อ ได้แก่
- Algorithm – ตัวอัลกอริทึมของโมเดล ซึ่งคิดโดยคน
- Data – ข้อมูลที่ใช้เทรน
- Compute – พลังประมวลผลในการเทรน
Algorithm
Algorithm ที่มาของอัลกอริทึมย่อมมาจากคน จากนักวิจัยด้าน AI ที่พยายามค้นหาอัลกอริทึมที่ดีขึ้นเรื่อยๆ ดังที่เราได้เห็นการแข่งทำลายสถิติ ImageNet ทุกปี
ขนาดของโมเดลเองก็ใหญ่ขึ้นเรื่อยๆ จากหลักร้อยล้านพารามิเตอร์ มาสู่หลักแสนล้านพารามิเตอร์ภายในเวลาเพียงไม่กี่ปี
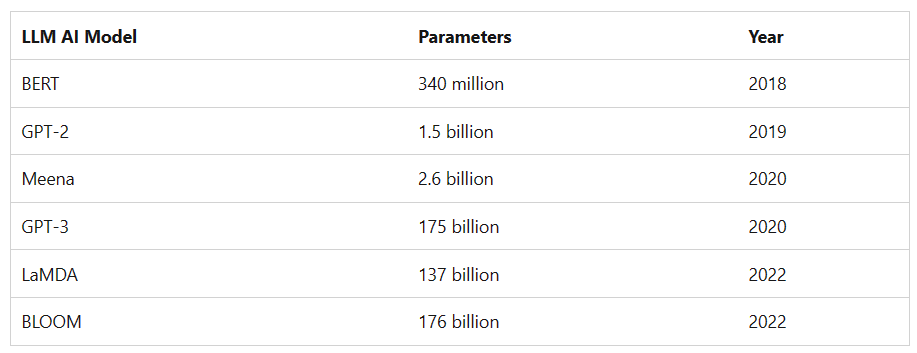
เปรียบเทียบพารามิเตอร์ของโมเดล LLM – Microsoft
บริษัทที่มีห้องวิจัย AI ขนาดใหญ่ ทำงานวิจัยระดับฐาน (fundamental research) เช่น Google Brain/DeepMind, FAIR, OpenAI ย่อมได้เปรียบ
เรื่องอัลกอริทึมนี่คนพูดถึงกันไปเยอะแล้ว คงไม่ต้องฉายหนังซ้ำอีกมากนัก
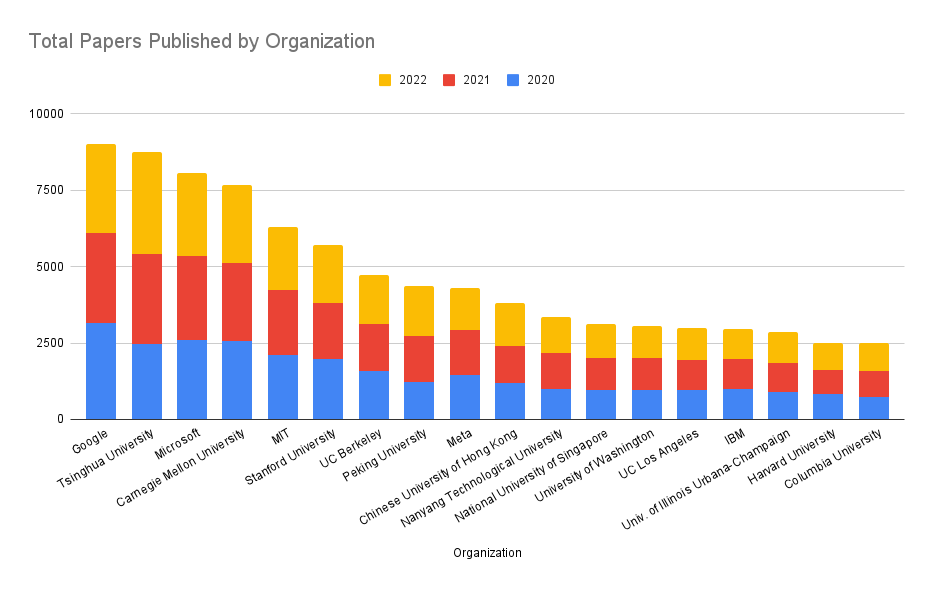
อันดับเปเปอร์ด้าน AI แยกตามองค์กร – Zeta-Alpha
Data
Data ข้อมูลที่ใช้เทรน เป็นสิ่งที่คนไม่ค่อยพูดถึงกันนัก แต่เบื้องหลัง GPT คือการจ้างพนักงานเอาท์ซอร์สในแอฟริกาเทรนข้อมูล ทำเรื่อง labeling ข้อมูล เพื่อนำมาใช้เทรน

A TIME investigation reveals the difficult conditions faced by the workers who made ChatGPT possible
 TIME
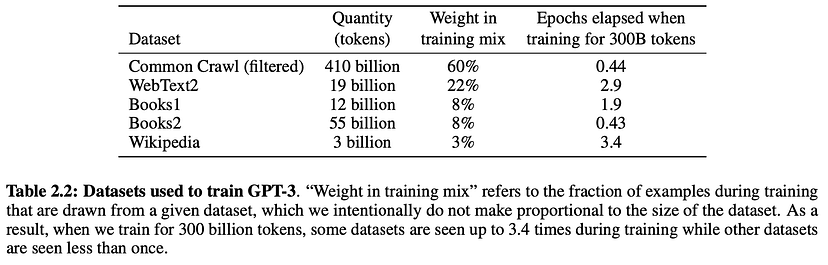
TIME ตัวอย่างข้อมูลที่ใช้เทรน GPT-3 จะเห็นการผสมผสานของข้อมูลสาธารณะ เช่น Common Crawl (ดูดจากเว็บ) หรือ Wikipedia (source)
ข้อมูลที่สามารถใช้เทรนโมเดลได้นั้นมีจำกัด โดยเฉพาะข้อมูลเฉพาะทาง เฉพาะโดเมน เฉพาะอุตสาหกรรม ช่วงหลังๆ เราจึงเห็นบริษัทที่เป็นเจ้าของข้อมูลเริ่ม “หวง” ข้อมูลลักษณะนี้มากขึ้น มีการคิดเงินค่าใช้ข้อมูล เช่น Reddit หรือฟ้องร้องการละเมิดลิขสิทธิ์ข้อมูล เช่น Getty
บริษัทที่มีข้อมูลเป็นของตัวเอง เช่น Google หรือ Facebook มีข้อมูลผู้ใช้ มีภาพถ่าย, Microsoft มีเอกสารในชุด Office มีโค้ดใน GitHub, Tesla มีข้อมูลภาพจากกล้องหน้ารถ ฯลฯ ย่อมได้เปรียบกว่าบริษัทอย่าง OpenAI หรือ Anthropic ที่จะหาข้อมูลมาเทรนได้ยากและราคาแพงขึ้นเรื่อยๆ
ตารางเปรียบเทียบแหล่งข้อมูล training dataset ของโมเดลต่างๆ
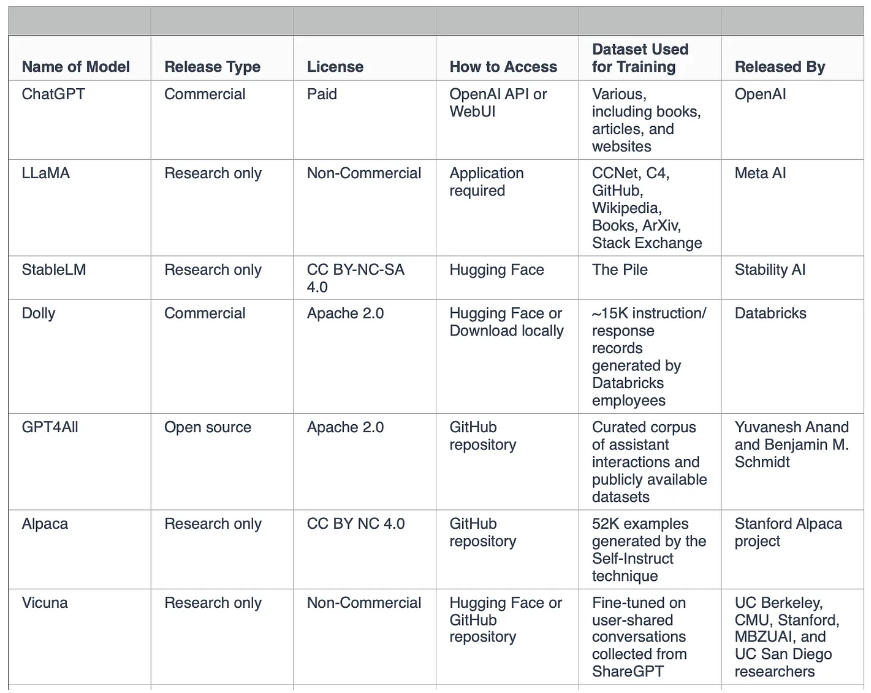
Source: Serop Baghdadlian
Compute
Compute สิ่งที่คนพูดถึงน้อยยิ่งกว่าข้อมูล คือพลังประมวลผลที่ใช้เทรนโมเดล (ยังไม่นับเรื่อง inference หรือการรันโมเดล) เพราะโมเดลยุคนี้มีขนาดใหญ่มากขึ้นเรื่อยๆ จึงต้องใช้คอมพิวเตอร์ที่มีขนาดใหญ่มากๆ ซึ่งเอาจริงแล้วมีเพียงไม่กี่บริษัทที่มีศักยภาพทำได้
ในงาน Build 2023 ของไมโครซอฟท์ Scott Guthrie ซึ่งเป็นผู้บริหารสูงสุดฝ่าย AI & Cloud ได้โชว์ภาพศูนย์ข้อมูลแห่งหนึ่งของ Azure ที่กำลังสร้างอยู่ เขาบอกว่าตั้งใจโชว์ภาพนี้ให้เห็น “สเกล” ว่าสิ่งที่พวกเรากำลังสร้างอยู่มันใหญ่ขนาดไหน

ศูนย์ข้อมูล AI ของ Microsoft Azure – source
บริษัทที่มีสเกลใหญ่ขนาดนี้ในโลก อาจมีไม่ถึง 10 บริษัทด้วยซ้ำ ตัวอย่างที่เคยเขียนข่าวเอาไว้ได้แก่
- Microsoft
- Meta
- Tesla
คอมพิวเตอร์ขนาดใหญ่เหล่านี้มักใช้ GPU เกรดศูนย์ข้อมูล ทำหน้าที่เป็นตัวเร่งประมวลผล AI (เพราะ GPU คำนวณทศนิยมได้ดีกว่า CPU) เจ้าตลาดนี้คือ NVIDIA ซึ่งใช้ทั้ง A100 (Ampere) รุ่นก่อนหน้า และ H100 (Hopper) รุ่นล่าสุด คู่แข่งโดยตรงในตลาดนี้คือ AMD Instinct แม้ยังตามหลังอีกไกล
ต้นทุนค่าเซิร์ฟเวอร์เหล่านี้ยังแพงมาก แม้ไม่มีใครรู้ตัวเลขจริง แต่มีการประเมินกันคร่าวๆ ว่าต้นทุนค่าเทรน GPT-3 อย่างน้อย 4 ล้านเหรียญ และต้นทุนค่ารันเดือนละ 40 ล้านเหรียญ

AI Accelerator
แต่หลายปีให้หลัง เราเริ่มเห็นหลายบริษัทไปไกลกว่า GPU คือไปถึงขั้นการออกแบบชิป AI Accelerator กันเอง เพื่อคัสตอมตาม workload ของงานที่เห็นจริงๆ
ตัวอย่างคือ TPU ของกูเกิลที่ทำมานานพอสมควรแล้ว (เริ่มปี 2016) ในเปเปอร์ล่าสุดของ TPUv4 เปิดเผยให้เห็นประเภทของ AI workload ว่ามีอะไรบ้าง เช่น งานจำพวก recommendation (DLRM) หรืองานพวก transformer (LLM) และจากตารางเราเห็นวิวัฒนาการของ workload ที่เปลี่ยนไปเรื่อยๆ ตามยุคสมัยด้วย
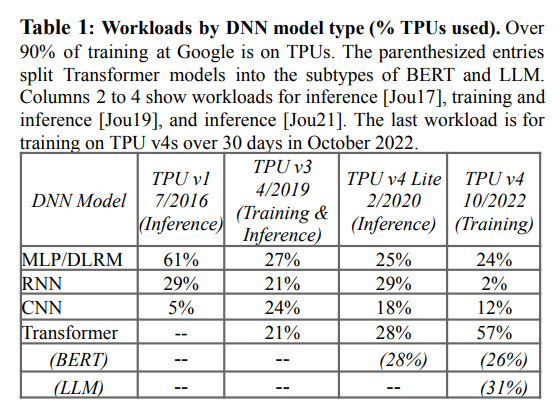
การที่มีรูปแบบของ workload เฉพาะทาง ที่มีปริมาณขนาดใหญ่มากๆ (ลองนึกถึงปริมาณ YouTube “แนะนำ” คลิปที่เราน่าจะสนใจในแต่ละวัน) การออกแบบชิปสำหรับ workload เฉพาะเหล่านี้จึงคุ้มค่ากว่าการใช้ Generic GPU ทั้งในแง่ราคา พลังงาน เวลาที่ใช้เทรน
อีกตัวอย่างคือ MTIA ของ Meta ที่เป็นชิปคัสตอมเหมือนกัน และออกแบบมาให้ตรงกับ workload ในที่นี้คือ PyTorch ซึ่งเป็นเฟรมเวิร์คที่ใช้ใน Meta โดยตรง แทนที่จะเป็น TensorFlow ของฝั่งกูเกิล แสดงให้เห็นถึงความจำเป็นของ optimization
นอกจาก Google TPU และ MTIA Meta แล้ว ยังมีบริษัทอื่นๆ ที่ออกแบบชิป AI Accelerator เฉพาะทางกันเองมากขึ้น (แม้ชื่อมันออกแฟนตาซีนิดนึง) เช่น
- Graphcore เรียกว่า IPU (Intelligence Processing Unit)
- Cerebras เรียกว่า Wafer-Scale Engine (WSE)
- SambaNova เรียกว่า Reconfigurable Dataflow Unit (RDU)
- Tesla D1 (ใช้ใน Dojo)
- AWS Trainium
- Intel Habana Gaudi (เกิดจาก Intel ซื้อ Habana)
- บริษัทจีนอีกจำนวนหนึ่ง
- รายชื่อทั้งหมดที่มีคนเคยรวบรวมไว้
เอาจริงแล้ว GPU กับ AI Accelerator อาจไม่ได้ทับซ้อนกันทั้งหมด 100% เราจะได้เห็นการใช้งานควบคู่กันไป เช่น งานบางส่วนที่เป็น generic ใช้ GPU, งานเฉพาะบางส่วนใช้ AI Accelerator ซึ่งทุกวันนี้ก็เริ่มเป็นแบบนั้นแล้ว
สำหรับคนที่สนใจเรื่อง AI Accelerator แนะนำบทความซีรีส์ 5 ตอนของ Adi Fuchs เขียนไว้ละเอียดเลย ตอนที่ 1, ตอนที่ 2, ตอนที่ 3, ตอนที่ 4, ตอนที่ 5
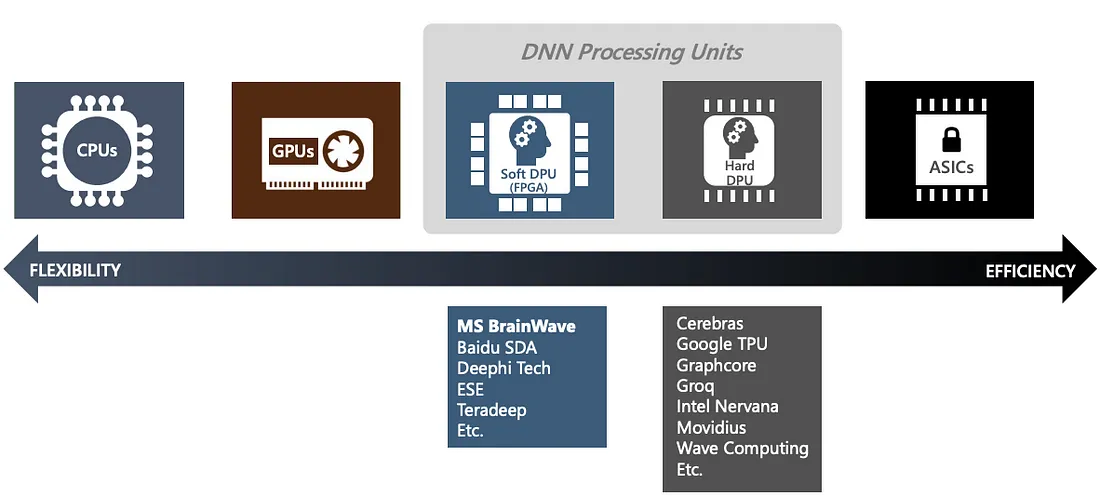
ภาพจาก Microsoft
ความพร้อมของเสาหลัก
บริษัทที่มีครบทั้ง 3 เสาหลัก ที่โดดเด่นที่สุดย่อมเป็น Google ที่มีสเกลใหญ่ครบทุกด้าน ตั้งแต่อัลกอริทึม (เป็นคนคิด Transformer, เป็นเจ้าของ DeepMind), มีปริมาณข้อมูลของตัวเองมหาศาล, เป็นผู้ให้บริการ Google Cloud + ออกแบบ TPU เอง
หากใครดูงาน Google I/O 2023 จะพอสรุปได้ว่า Google เริ่มลงตัวกับเรื่องนี้แล้ว (หลังกล้าๆ กลัวๆ เรื่องโมเดลมานาน) และกำลังดันพลัง AI ลงในสารพัดบริการของตัวเอง
บริษัทที่มี 3 เสาหลักครบเหมือนกัน แต่อาจไม่อลังการเท่ากับของ Google ได้แก่ Meta (อาจเป็นเพราะไปเน้น Metaverse มากไปหน่อยในช่วงหลัง) และ Tesla (เน้น vision อย่างเดียวตามธุรกิจของบริษัท)
ส่วนคู่ Microsoft/OpenAI เป็นการจับมือที่เข้ากันดีคือ OpenAI มี algorithm ส่วน Microsoft มี data/compute ขาดฝั่งใดฝั่งหนึ่งไปก็ไม่เกิดอีกเหมือนกัน
Amazon เป็นบริษัทที่มีครบทั้ง data/compute แต่ฝั่ง algorithm กลับเงียบไปมากเกินกว่าที่ควรจะเป็น ก็ไม่แน่ใจเหมือนกันว่าเกิดอะไรขึ้น อันนี้คล้ายกับกรณีของ Apple ที่ควรไปได้ไกลกว่านี้

 Decrypt
Decrypt หมายเหตุ: บทความนี้ได้รับคำแนะนำจากคุณต้า Ta Virot Chiraphadhanakul แห่ง Skooldio ในการปรับปรุงให้สมบูรณ์ขึ้น ขอขอบคุณมา ณ ที่นี้