คลื่น Generative AI ที่ผงาดขึ้นมาตั้งแต่ปลายปี 2022 สร้างความเปลี่ยนแปลงในโลกหลายอย่าง แต่ด้านที่คนไม่ค่อยพูดถึงกันนักคือ user interface หรือวิธีการสื่อสารระหว่างมนุษย์กับคอมพิวเตอร์
การทำงานของโมเดลภาษา LLM ที่มีลักษณะเป็น “เครื่องเดาคำ” เปลี่ยนโลก GUI แบบดั้งเดิม (เมาส์คลิกวัตถุบนจอ ที่วิวัฒนาการมาเป็นการใช้นิ้วสัมผัส แต่ก็ยังอยู่บนฐานเดิม) ให้กลับมาเป็นโลกที่ขับเคลื่อนด้วย text-based หรือที่เราเรียกด้วยภาษาแบบใหม่คือ prompt
ตัวอย่างที่ชัดเจนที่สุดคือ การเขียนโปรแกรมที่กำลังเปลี่ยนจากการใช้ GUI (ผ่านซอฟต์แวร์ IDE) กลับมาสู่การใช้ CLI หรือ command-line แบบยุคดั้งเดิม เพียงแต่เปลี่ยนจากการที่มนุษย์พิมพ์เองทั้งหมด มาเป็นการสั่งให้โมเดลช่วยเขียนให้แทน
คำถามที่น่าสนใจคือ แล้ว user interface แบบใดที่เหมาะสำหรับโลกยุค AI กันแน่ ตกลงแล้วเรายังควรอยู่กับ GUI หรือเปลี่ยนมาเป็นการสนทนาโต้ตอบ (ด้วยข้อความหรือเสียงที่แปลงเป็นข้อความ) จะดีกว่า
ในรอบสัปดาห์ที่ผ่านมา มีงานออนไลน์ The Android Show ที่เป็นการประกาศของใหม่ในโลก Android ประจำปี (เดิมทีอยู่ใน Google I/O แต่ตอนหลังถูกแยกออกมา) มีของใหม่อย่างหนึ่งที่น่าสนใจมากและน่าจะตอบคำถามนี้ได้ด้วย นั่นคือ Googlebook โน้ตบุ๊กแบรนด์ใหม่ของกูเกิล ที่มาพร้อมระบบปฏิบัติการ Chrome OS เวอร์ชันอัพเกรด (บ้างเรียกตามโค้ดเนมว่า Aluminium OS แต่ยังไม่ใช่ชื่อทางการ)
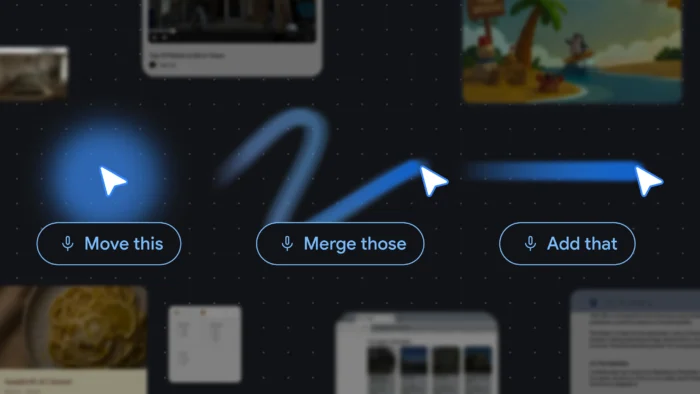
ฟีเจอร์เด่นอย่างหนึ่งของ Googlebook เรียกว่า Magic Pointer มันเป็นการ “เขย่า” เคอร์เซอร์เมาส์ แล้ว OS จะเข้าสู่โหมดพิเศษ ที่เราสามารถเลือกวัตถุบนหน้าจอ เช่น รูป ข้อความ เพื่อส่งให้ AI ทำอะไรบางอย่าง (ค้นหาข้อมูล ถามตอบ รวมรูปภาพเข้าด้วยกัน ฯลฯ) ได้
เขียนบรรยายแบบนี้ อาจนึกภาพตามกันไม่ค่อยออก ดูคลิปกันน่าจะเข้าใจง่ายกว่า
การเอารูปภาพหลายๆ รูป ส่งต่อไปให้ Generative AI รวมเป็นภาพเดียวกันได้อย่างมหัศจรรย์ มันอาจไม่ใช่สิ่งที่น่าตื่นเต้นใน พ.ศ. นี้แล้ว แต่สิ่งที่ผมสนใจคือ interface หรือวิธีสั่งการที่อาจเปลี่ยนไปจากเดิม
ทุกวันนี้ถ้าเราอยากหาข้อมูลจากภาพบางอย่าง หรือ อยากรวมวัตถุในรูปภาพ 2-3 ภาพเข้าด้วยกัน กระบวนการสั่งงานคือ เราเซฟรูปที่ต้องการลงเครื่อง –> เปิดเว็บ/แอพ AI ขึ้นมา –> เลือกรูปที่ต้องการ –> เขียน prompt สั่งงาน –> รอ AI ทำงาน –> ได้ผลพอใจ –> เซฟรูปลงเครื่องไปใช้งานต่อ
กระบวนการทำงานของ Magic Pointer ทำให้ขั้นตอนเหล่านี้ลดลง เราแค่เขย่าๆ เมาส์ 1-2 ปี –> จิ้มรูปหรือข้อความบนหน้าจอ (จิ้มหลายรูปได้) –> เลือกคำสั่งจากเมนู popup ที่โผล่ขึ้นมาบนจอ –> รอผลลัพธ์
ผมคิดว่าถ้าใครเคยใช้ Circle to Search บนมือถือ น่าจะพอเห็นภาพเพราะแนวคิดมันใกล้เคียงกัน แค่เปลี่ยนจากการเอานิ้วลาก มาเป็นการใช้เมาส์บนคอมพิวเตอร์แทน
ฟังดูเหมือนไม่ค่อยมีอะไร แต่ผมกลับพบว่าแนวคิดเบื้องหลังของ Magic Pointer ลึกซึ้งกว่าที่คิด
ฟีเจอร์นี้เกิดจากทีมวิจัยของ Google DeepMind ที่ทดลองค้นหา “UI ที่เหมาะสมกับโลก AI” หลายๆ แบบ จนมาลงตัวที่ฟีเจอร์ Magic Pointer
แนะนำว่าดูคลิปแล้วเข้าใจง่ายกว่ามาก
ทีมวิจัยบอกว่าต้องการแก้ปัญหา AI ทำงานแต่ในหน้าต่างตัวเอง ไม่เชื่อมกับโลกภายนอก ถ้าเราอยากให้ AI เข้าใจอะไร เราจำเป็นต้องลากสิ่งต่างๆ เข้าไปในหน้าต่างของ AI ส่งผลให้ flow การทำงานของผู้ใช้ไม่ไหลลื่นเท่าที่ควร
เป้าหมายของทีมวิจัยคือต้องการให้กลับทิศกัน นั่นคือ AI เข้าใจโลกภายนอกด้วย ผู้ใช้เห็นอะไร AI เห็นสิ่งนั้น ทำงานได้ลื่นไหลกว่าเดิม
อีกปัญหาของโลกยุค AI คือ “ความแม่นยำ” (precision) มันหายไปครับ ในโลกยุค GUI เราเห็นว่าปุ่มอยู่ตรงไหน กดตรงนี้แล้วได้อะไร เคอร์เซอร์เมาส์มีความแม่นยำระดับพิกเซล แต่พอเป็นยุค AI ที่สั่งงานด้วยข้อความ เราสั่งงานได้แค่คร่าวๆ ว่า “ลบหมวกสีแดงในภาพ” แต่ถ้าในภาพมีหมวกสีแดงหลายใบ เราจะเริ่มสั่งได้ไม่ค่อยแม่นแล้ว “ลบหมวกสีแดงอันขวาในภาพ” ขวาไหน คนที่เท่าไรจึงจะพอดี
ปัญหาข้อสองแก้ได้ด้วยการใช้ GUI แบบดั้งเดิม ร่วมกับการ prompt แบบโลกยุค AI ไปซะเลย ยิ่งถ้าใช้กับการ prompt ด้วยเสียงพูด มันยิ่งเป็น user interface ที่ทรงพลัง ในคลิปข้างต้นเราจะเห็นการสั่งงานแบบ this and that โดยใช้เคอร์เซอร์ ร่วมกับเสียงพูด “ลบหมวกแดงอันนี้ (เคอร์เซอร์ชี้) แล้วย้ายไปไว้ตรงนั้น (เคอร์เซอร์ชี้)” ผมว่าเป็นการสั่งงานที่ลงตัวมาก
ส่วนปัญหาข้อแรก เรื่อง AI ทำงานข้ามหน้าต่างไม่ได้ ในเมื่อกูเกิลเป็นเจ้าของ OS เอง + เป็นเจ้าของโมเดลเอง มันก็แก้ไม่ยาก จับ AI ไปฝังใน OS ที่สามารถทำงานได้ข้ามหน้าต่าง เห็นวัตถุบนจอทั้งหมด ก็แก้ปัญหาเหล่านี้ได้แล้ว
ทั้งหมดนี้เลยออกมาเป็น Magic Pointer โดยคำอธิบายของกูเกิลน่าสนใจมาก
For decades, computers have only tracked where we are pointing. AI can now also understand what the user is pointing at.
This transforms pixels into structured entities, such as places, dates, and objects, that users can interact with instantly.
คอนเซปต์มาดีมาก ที่เหลือคงต้องรอดูว่าใช้จริงๆ แล้วมันจะเวิร์คอย่างที่โฆษณาไว้หรือเปล่านั่นเองครับ