
1) เรื่องที่ผมกำลังสนใจศึกษาอยู่ในตอนนี้คือเรื่อง “การทำงานสมอง” (ไว้มีโอกาสจะเขียนถึงต่อไป) ด้วยเหตุผลว่าพอ AI กลายเป็นประเด็นถกเถียงกันมากๆ ว่าจะมาแทนมนุษย์หรือไม่ ผมกลับไม่มีคำตอบที่ดีมากพอจะตอบใครๆ ด้วยสาเหตุ (ที่ผมมาค้นพบเองในภายหลัง) ว่าตัวเองไม่มีความเข้าใจเรื่อง “Intelligence” ดีมากพอ จนสามารถไปเปรียบเทียบได้ว่า Artificial Intelligence มันเหมือนหรือต่างกับ Human Intelligence อย่างไร
2) Fei Fei Li เป็น “เจ้าแม่” ของวงการ AI มายาวนาน ผลงานของเธอที่ประจักษ์โด่งดังในสายงานวิจัย โดยเฉพาะฝั่ง “ภาพ” (computer vision) คือ ImageNet ที่เป็นคลังภาพมาตรฐาน สำหรับนักวิจัยใช้ทดสอบว่าอัลกอริทึมของตนแยกแยะภาพได้ดีเท่ามนุษย์แล้วหรือยัง
อาชีพหลักของ Fei Fei Li คือเป็นอาจารย์ที่ Stanford แต่ก็วนเวียนอยู่กับ Google อยู่บ่อยครั้ง ผมเคยไปนั่งฟังเธอพูดแบบตัวเป็นๆ ครั้งหนึ่งตอนไปงาน Google I/O ปี 2018 ซึ่งเป็นปีที่เธอทำงาน full time ที่ Google พอดี (ทำอยู่ปีเดียวอีกต่างหาก) เนื้อหาฟังรู้เรื่องบ้างไม่รู้เรื่องบ้าง แต่ที่จำได้คือคนต่อคิวฟังมหาศาลอย่างกับร็อคสตาร์ ทั้งที่คาแรกเตอร์เธอนั้นเป็นนักวิจัยสุดๆ ถ้าจำไม่ผิดคือผมโชคดีมากที่ฟังเซสชันก่อนหน้าแล้วไม่ต้องออกจากเต๊นต์นั้น เลยมีโอกาสได้ฟังเธอตัวจริงสักครั้ง
นี่ต้องไปค้นรูปใน Google Photos มาดูเลยว่าตอนนั้นที่ไปดูในงาน I/O บรรยากาศมันเป็นอย่างไร

3) ช่วงหลัง Fei Fei Li กลับมาออกสื่ออีกครั้ง ล่าสุดไปพูดในงาน TED Talk เห็นคลิปที่ อ.ต้า แชร์มา พอมีเวลานั่งฟัง เปิดคลิปมาแล้วแทบตกเก้าอี้ เพราะเป็นเรื่องที่ผมสนใจพอดี
Fei Fei Li เริ่มต้นด้วยการบอกว่า สิ่งมีชีวิตชั้นต่ำในอดีตนั้น “ไม่มีตา” เพราะโลกไม่มีแสงสว่าง เมฆบังแสงอาทิตย์ไปหมด เมื่อเมฆเริ่มคลี่คลายออก แสงเริ่มส่องถึงผิวโลก สิ่งมีชีวิตก็ค่อยๆ ปรับตัว สร้างเซ็นเซอร์รับแสงทางชีวภาพเข้ามาอย่างช้าๆ กลายมาเป็นตา การมีตาทำให้มองเห็นและเข้าใจสิ่งรอบตัว เกิดเป็นการกระทำ (action) ว่าเห็นภาพแล้วไปทำอะไรต่อ และกลายเป็นปัญญา (intelligence) ขึ้นมา เกิดเป็นยุค Cambrian explosion ที่สิ่งมีชีวิตวิวัฒนาการอย่างก้าวกระโดด ที่นักชีววิทยาชอบอ้างถึงกัน
กระบวนการเหล่านี้ใช้เวลาเป็นล้านปี


สิ่งที่เธอทำอยู่ในอดีตคืองานด้าน computer vision พัฒนาอัลกอริทึมให้แยกแยะรูปภาพได้ว่าเป็นภาพเกี่ยวกับอะไร แต่ปัจจุบัน งานด้าน vision มันก้าวหน้าไปมาก ทั้งฝั่งการแยกแยะรูปภาพ และการสร้างรูปภาพ (image generation) ตามคำบอกเหมือนที่เราใช้กันทุกวันนี้
สิ่งที่เธอจะทำในขั้นถัดไปคือ Spatial Intelligence หรือปัญญาในการเข้าใจมิติ (space) ซึ่งเธอมองว่ามันคือวิวัฒนาการขั้นถัดไปของปัญญาประดิษฐ์

ชื่ออาจฟังดูซับซ้อนเข้าใจยาก ซึ่ง Fei Fei Yi ยกตัวอย่างงานวิจัยล่าสุดของเธอและลูกศิษย์ ที่สอนให้ “แขนกล” สามารถหยิบขนมปังมาต่อกันเป็นแซนด์วิชได้ ปกติแล้วเราต้องสร้างโมเดลหรืออัลกอริทึมเรื่อง “สร้างแซนด์วิช” ขึ้นมาเป็นการเฉพาะ แล้วแขนกลนี้จะไม่สามารถไปทำอย่างอื่นๆ (เช่น จัดดอกไม้) ได้
แต่ถ้าพัฒนาเรื่อง spatial intelligence สอนให้โมเดลเรียนรู้สภาพแวดล้อมจำลองแบบต่างๆ (digital twins แบบที่เคยเขียนไป) มากพอในระดับหนึ่งแล้ว เมื่อเรานำแขนกลมาวางไว้ข้างขนมปัง ผัก ชีส แล้วสั่งว่า “ทำแซนด์วิชให้หน่อย” ปัญญาประดิษฐ์ของเราจะมีความเข้าใจภาพที่มองเห็น สะท้อนต่อไปยังมิติรอบตัวว่ามีอะไรอยู่บ้าง (spatial intelligence) และสามารถทำแซนด์วิซให้เราได้เลย
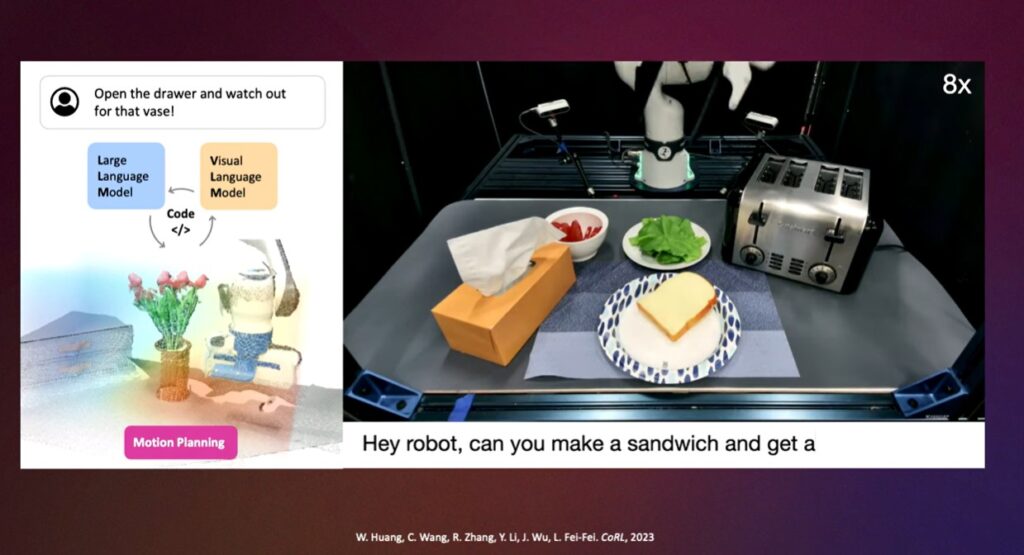
Fei Fei Li บอกว่าพัฒนาการของ spatial intelligence จะส่งผลให้เกิด loop การเรียนรู้และทำความเข้าใจไปเรื่อยๆ และกลายเป็น Digital Cambrian Explosion ในท้ายที่สุด ซึ่งเธอมองว่านี่คือโอกาสอันดีที่เราจะสอนให้ปัญญาดิจิทัลเหล่านี้เรียนรู้โลกที่เราอยู่ในปัจจุบันว่าเป็นอย่างไร และจะอยู่ร่วมกันต่อไปอย่างไร
คลิปเต็ม 15 นาทีว้าวมาก แนะนำอย่างยิ่งให้ดูกัน เวลาเจออาจารย์เก่งๆ แบบนี้ดูแล้วเปิดหูเปิดตาอย่างมากเลย