การเปิดตัว GPT-5 ในสัปดาห์ที่ผ่านมา อาจไม่ประสบความสำเร็จมากนัก เพราะความคาดหวังสูงเทียมฟ้า (hype กันมายาวนานข้ามปี) แถมพี่แซมเองก็โม้ไว้ซะเยอะในคลิปเปิดตัวว่าความสามารถ GPT-5 เทียบเท่าปริญญาเอก เมื่อโมเดลจริงมีปัญหาหลายจุด เช่น บวกเลขง่ายๆ ยังผิด ทำกราฟก็ยังผิด ทำให้ OpenAI เสียรังวัดไปพอสมควร
แต่โพสต์นี้ไม่ได้เป็นการมาวิจารณ์ OpenAI แต่อย่างใด
LLM กำลังจะถึงทางตัน?
ประเด็นคือผมไปอ่าน โพสต์วิจารณ์ GPT-5 ของ Gary Marcus นักวิชาการคนดังของโลก AI ที่เปิดศึกกับกลุ่มแฟนบอยและ AI bros มาตลอด แกชี้ประเด็นว่าข้อจำกัดของ GPT-5 อาจเป็นสัญญาณว่าเราใกล้มาถึงทางตันของโมเดลภาษา LLM แล้ว
โดยแก่นแล้ว LLM มันคือเครื่องทายคำขนาดใหญ่ ที่ไม่มีตรรกะในตัว แต่ด้วยเทคนิคหลายๆ อย่าง เช่น Chain-of-Thought (CoT) Reasoning ทำให้มัน “ดูเหมือนจะ” มีเหตุมีผลขึ้นมา แต่นั่นอาจเป็นภาพลวงตา (mirage) ว่ามันเวิร์ค ทั้งที่จริงๆ มันอาจไม่เวิร์คเลยก็ได้
Marcus ยังพูดถึงเทคนิคการขยายโมเดลให้ใหญ่ขึ้นเรื่อยๆ ตามหลัก Scaling Laws ซึ่งเป็นพัฒนาการกระแสหลักของวงการ LLM ในช่วงประมาณ 5 ปีที่ผ่านมา ว่าสุดท้ายแล้ว Scaling เพียงอย่างเดียว ไม่มีทางนำเราไปสู่ AGI อย่างที่ฝันกันหรอก
Nobody with intellectual integrity should still believe that pure scaling will get us to AGI.
แนวคิดของ Marcus คล้ายๆ กับของ Yann LeCun แห่ง Meta FAIR ที่พูดมาตลอดว่า LLM อย่างเดียวไม่เวิร์ค ถ้าเราอยากสร้างปัญญาประดิษฐ์ที่ทัดเทียมมนุษย์ ต้องสร้าง “ระบบคิด” (อ. Yann ใช้คำว่า World Model หรือโมเดลการตอบสนองต่อโลกภายนอก) ขึ้นมาด้วย
แต่พอ Marcus แตะเรื่อง Scaling Laws แล้วผมกำลังอ่านเรื่องนี้พอดี (จากสไลด์ของ Vlad Feinberg แห่ง DeepMind) เลยอยากเขียนเรื่องนี้ไว้สักหน่อย
Scaling Laws
คำว่า Scaling Laws อาจแปลเป็นภาษาไทยได้ว่า “กฎแห่งการสเกล”
แต่ถึงแม้ในชื่อมีคำว่า Laws ก็ตาม จริงๆ แล้วมันคือปรากฏการณ์ที่สังเกตพบ (empirical laws) มากกว่ากฎตายตัวที่ยืนยันพิสูจน์ได้จริงๆ แบบเดียวกับกฎทางฟิสิกส์
ถ้าให้เทียบเคียง ผมคิดว่ามันคล้ายกับ “กฎของมัวร์” ที่เราคุ้นเคยกันในโลกของซีพียูและชิปประมวลผลมากกว่า คือเป็นข้อสังเกต (observation) ที่กอร์ดอน มัวร์ สังเกตพบว่าวงการเซมิคอนดักเตอร์มันมีธรรมชาติอย่างไร
จุดกำเนิดของ Scaling Laws เกิดจากทีมวิจัยของ OpenAI ตีพิมพ์เปเปอร์ในปี 2020 ชื่อว่า Scaling Laws for Neural Language Models (ถือเป็นเปเปอร์ที่สำคัญมากของวงการ ถัดจากเปเปอร์ Attention Is All You Need ในปี 2017 ที่เป็นจุดเริ่มต้นของโมเดลตระกูล Transformer เลยก็ว่าได้)
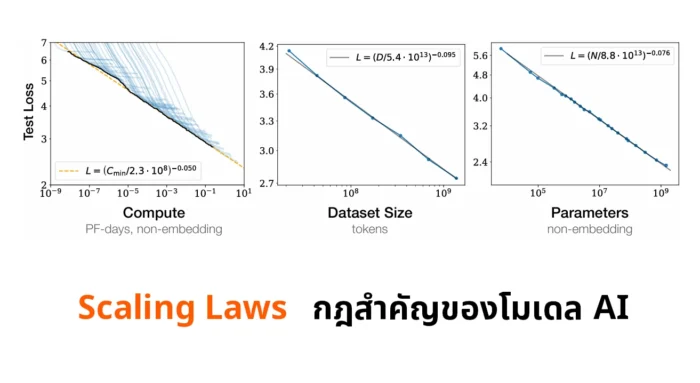
ใจความหลักของเปเปอร์นี้คือ ทีมวิจัยสังเกตพบว่า ขนาดของโมเดล (model size) ขนาดของชุดข้อมูล (dataset size) และพลังประมวลผลที่ใช้เทรนโมเดล (compute) มีความสัมพันธ์กัน
หากเราต้องการเพิ่มขีดประสิทธิภาพ (performance) ของโมเดล (วัดจากค่าความผิดพลาด test loss ที่ลดลง) เราจำเป็นต้องขยายทั้ง 3 ปัจจัยคือ ขนาดโมเดล ขนาดข้อมูล และพลังประมวลผลไปพร้อมๆ กัน จะเลือกขยายเฉพาะบางปัจจัยไม่ได้
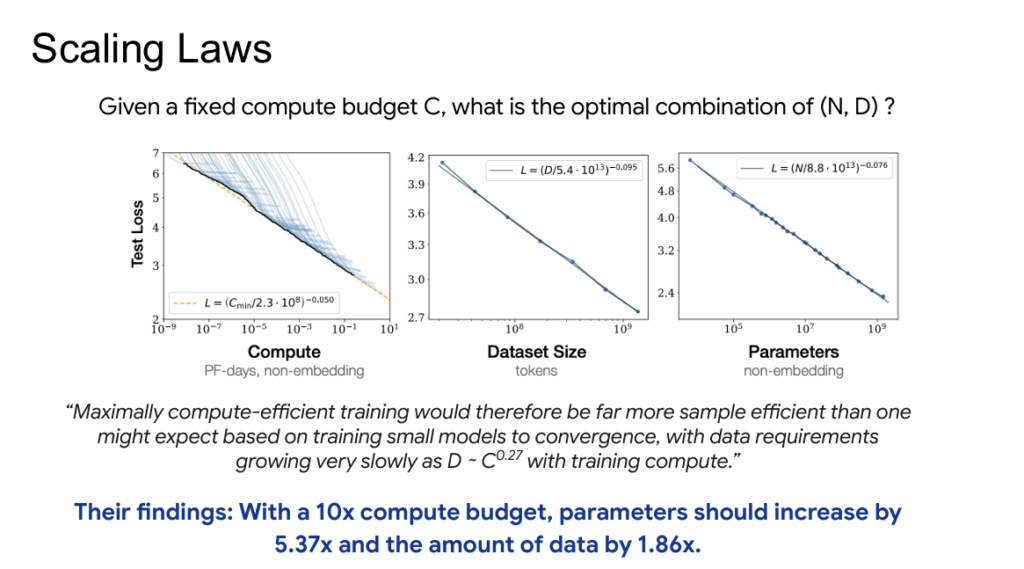
ความสัมพันธ์ของ performance กับปัจจัยทั้ง 3 ยังเป็นแบบ power-law คือเป็นเลขยกกำลัง (ชาร์ทที่เห็นเป็น log scale เราเลยเห็นเป็นเส้นตรง) และความสัมพันธ์ของปัจจัยทั้ง 3 ข้อมีค่าคงที่ชุดหนึ่งกำกับเอาไว้
With a 10x compute budget, parameters should increase by 5.37x and the amount of data by 1.86x
ผลจากการค้นพบนี้ ทำให้ตัวโมเดลมีขนาดโตเร็วกว่าขนาดของชุดข้อมูล (หากเราถือว่าเรามีพลังประมวลผลจำกัด เอาไปโตฝั่งโมเดลดีกว่า) และมันกลายเป็นหลักสำคัญที่กำหนดทิศทางของอุตสาหกรรม AI ในรอบ 5 ปีที่ผ่านมาหลังเปเปอร์นี้ตีพิมพ์นั่นเอง
ตรงนี้อธิบายได้ว่าทำไมโมเดล LLM มันแข่งกันใหญ่ขึ้นเรื่อยๆ อย่างรวดเร็วในช่วงหลัง เพราะหากจะให้มันเก่งขึ้น เส้นทางหลักคือทำให้โมเดลมันใหญ่ขึ้นนั่นเอง (the bigger is better)
เกร็ดเล็กๆ อย่างหนึ่งคือ ทีมวิจัยของ OpenAI ทีมนี้บางคนคือ Jared Kaplan และ Dario Amodei ในเวลาต่อมาได้ลาออกมาก่อตั้งบริษัท Anthropic ซึ่งกลายเป็นหนามทิ่มแทงใจ OpenAI อยู่ในตอนนี้
Dario Amodei ซีอีโอของ Anthropic เพิ่งไปออกรายการของ Lex Fridman เล่าถึงเรื่องนี้โดยเฉพาะ เขาบอกว่าตัวเองจบฟิสิกส์มา และพบว่าในธรรมชาติมีปรากฏการณ์ทางฟิสิกส์บางอย่างคล้ายๆ กัน เช่น 1/f noise ทำให้เขาเริ่มสังเกตเห็นปรากฏการณ์แบบเดียวกันกับโมเดล LLM และนำมาสู่ Scaling Laws ในที่สุด
Chinchilla Paper
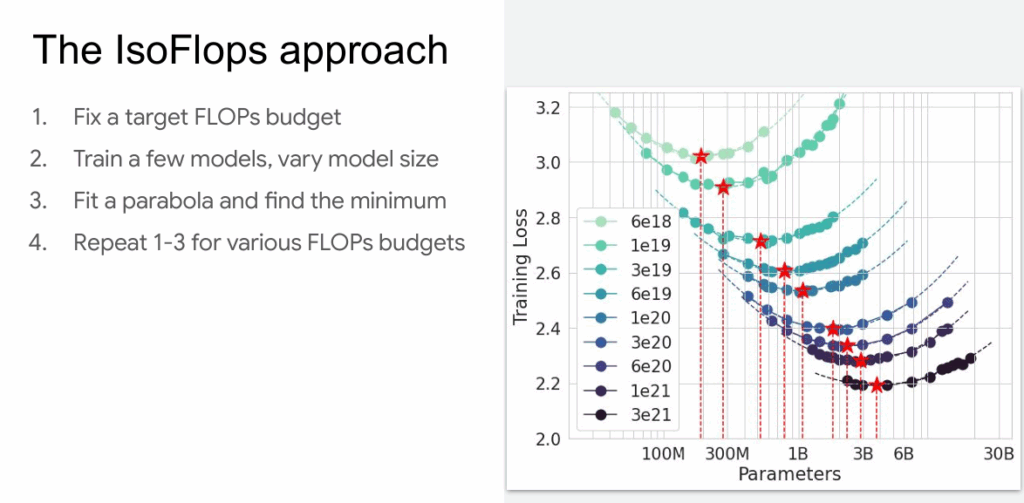
หลังจากนั้นในปี 2022 ทีมวิจัยของ DeepMind ได้ลองศึกษาเปเปอร์ของ Scaling Laws อย่างละเอียด และพบจุดอ่อนในเปเปอร์ว่าใช้ค่าประมาณการณ์ loss ที่ไม่ละเอียดมากพอ แล้วเอาไปประเมินค่า loss แบบภาพรวม
ทีมวิจัย DeepMind จึงลองสร้างโมเดลตัวใหม่ชื่อ Chinchilla (เป็นสัตว์ตระกูลหนูสายพันธุ์หนึ่งในอเมริกาใต้ ผมเข้าใจว่าตั้งชื่อล้อกับโมเดลอีกตัวของ DeepMind ชื่อ Gopher) โดยสร้างโมเดลมาหลายๆ ขนาดมากขึ้น
เมื่อได้โมเดลหลายๆ ขนาดแล้วลองนำไปพล็อตกราฟเทียบกับพลังประมวลผล (compute) และขนาดชุดข้อมูล (dataset size) แล้วได้ออกมาเป็นเส้นที่มีดาวสีฟ้าในภาพ นั่นคือความสัมพันธ์ระหว่างขนาดโมเดลกับขนาดชุดข้อมูล มีความชัน 0.5 แปลว่าทั้งสองปัจจัยจะเติบโตไปแบบเท่าๆ กัน (scale equally)
ตัวเลขนี้ต่างจากสูตร Scaling Laws ต้นฉบับที่ทีมของ Kaplan สังเกตพบ (เส้นประในภาพ) ผลกระทบของมันแปลว่า โมเดลควรมีขนาดเล็กลงได้หน่อย (ถ้าเทียบกับชุดข้อมูลขนาดเดิม) ไม่จำเป็นต้องใหญ่ระดับเดียวกับสูตร Scaling Laws ของเดิม จึงสามารถประหยัดทรัพยากรการประมวลผลลงได้ หรือจะนำทรัพยากรนี้ไปเทรนให้นานขึ้นแทนก็ได้
เปเปอร์นี้ถูกตีพิมพ์ในชื่อว่า Training Compute-Optimal Large Language Models
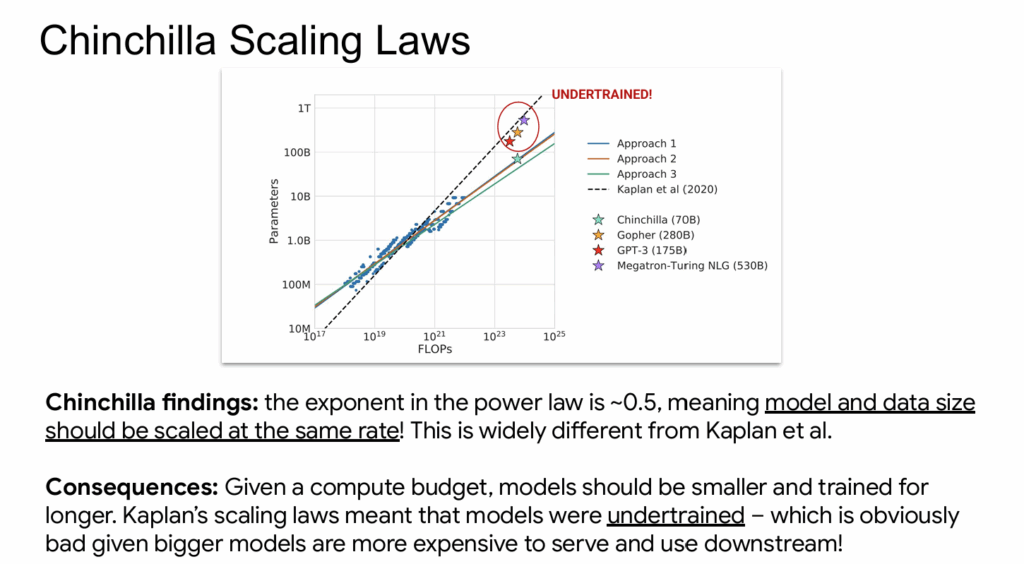
ถ้าให้สรุปคือ Scaling Laws ดั้งเดิมเป็นตัวกำหนดทิศทางภาพใหญ่ แล้ว Chinchilla Paper มาปรับจูนสัดส่วนตัวเลขใหม่หน่อย แต่ในภาพรวมแล้วมันยังไปทางเดิมคือ โมเดลขนาดใหญ่ขึ้นเรื่อยๆ
อนาคตของ Scaling Laws
แม้ว่าช่วงหลังๆ เราพูดกันเยอะว่า Scaling Laws ดูเหมือนใกล้ถึงทางตัน แต่ ณ ปัจจุบัน มันยังไม่ตันง่ายๆ ด้วยเหตุผลว่าทรัพยากร compute ที่ดูเหมือนมีจำกัด จริงๆ แล้วไม่จำกัดหากเรามีเงินมากพอ (ฮา)
ในช่วง 2-3 ปีหลัง เราจึงเห็นบริษัทยักษ์ใหญ่ของโลกไม่กี่รายที่รวยจัดๆ มีเครื่องผลิตเงินของตัวเอง เช่น Google, Meta, Microsoft แข่งกันลงทุนสร้างศูนย์ข้อมูลขนาดใหญ่ขึ้นเรื่อยๆ เพื่อเป้าหมายปลายทางว่าต้องการสร้างโมเดลที่เก่งที่สุดเท่าที่ทำได้ และต้องทำได้ก่อนคู่แข่ง
อย่างไรก็ตาม ข้อจำกัดของการขยายขนาดโมเดลกลับมาจากปัจจัยอื่นแทน นั่นคือ เราใช้ข้อมูลสำหรับเทรนโมเดลไปเกือบหมดอินเทอร์เน็ตแล้ว หากเราต้องการทำลายข้อจำกัดนี้ ทางแก้ที่เป็นไปได้คือ
- ใช้ข้อมูลประเภทอื่น (multimodal) นอกจากข้อความ ซึ่งข้อมูลประเภทที่วงการ AI ฝากความหวังเอาไว้เยอะคือ ภาพหรือคลิปจากกล้องมือถือ เพราะสามารถผลิตได้ไม่จำกัด
- ใช้ข้อมูลสังเคราะห์ (synthetic data) ที่สร้างด้วย AI อีกที ตรงนี้มีคำถามตามมาเหมือนกันว่าข้อมูลสังเคราะห์จะมีคุณภาพมากแค่ไหน คงต้องติดตามกันต่อไปในระยะยาว
ทิศทางอีกอย่างของ Scaling Laws คือการที่โมเดลขนาดใหญ่ขึ้นเรื่อยๆ มันแพงขึ้นเรื่อยๆ ทั้งค่าเทรนและค่ารัน (inference) แม้เป็นบริษัทใหญ่โตแค่ไหนก็ตาม สุดท้ายแล้ว เงินมันก็มีจำกัดอยู่ดี
อย่ากระนั้นเลย เรามาสร้างโมเดลที่มีประสิทธิภาพในการรันดีขึ้นดีกว่า แนวทางนี้เรียกว่า Inference-Aware Scaling ที่พยายามแก้จุดอ่อนของ Chinchilla Paper ที่ไม่สนใจต้นทุนค่ารัน โดยสร้างโมเดลขนาดเล็กลง ชดเชยด้วยข้อมูลใหญ่ขึ้น และแลกมาด้วยพลังประมวลผลตอนเทรนที่เพิ่มขึ้น (แต่เทรนแค่ครั้งเดียวไง) เพื่อให้ได้โมเดลที่ประสิทธิภาพพอๆ กัน แต่ประหยัดกว่าในการรัน (เพราะรันหลายรอบ)
เปเปอร์นี้มีชื่อว่า Beyond Chinchilla-Optimal: Accounting for Inference in Language Model Scaling Laws
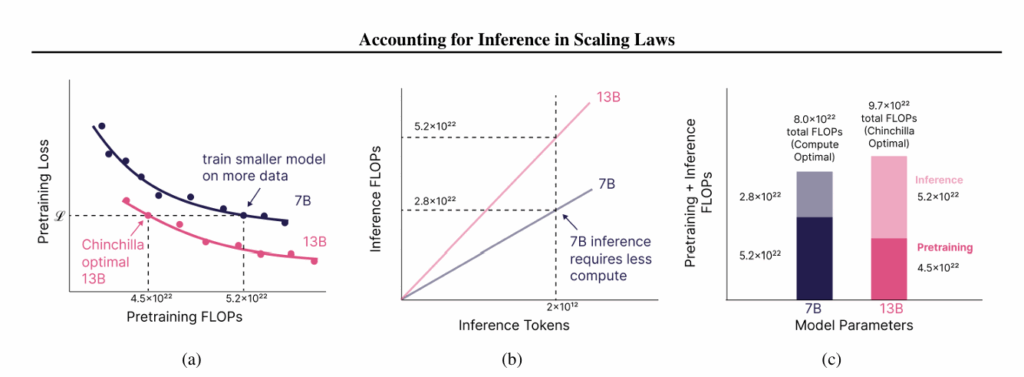
บทความนี้อธิบายเรื่องการแบ่งยุคของ Scaling Laws ไว้ค่อนข้างดี และมีตัวอย่างให้เห็นว่าโมเดล LLM แต่ละยุคใช้แนวทางต่างกันอย่างไร

แนวทางของ Google กับ Gemini ช่วงหลังก็ดูไปในทิศทางนี้ นั่นคือ ใช้โมเดลขนาดเล็กลง แต่ตอบคำถามได้เร็วกว่า ให้บริการลูกค้าได้ปริมาณเยอะกว่า เนื่องจากลูกค้าทั่วไปส่วนใหญ่ ไม่ได้ต้องการอะไรที่ซับซ้อนมาก ขอแค่ตอบดีพอประมาณ แต่ตอบเร็วก็พอ เราจึงเห็นกูเกิลหันมาเน้นโมเดลตระกูล Flash และ Flash-Lite อย่างมาก และเน้นทำต้นทุนค่ารันให้ถูกมากๆ นั่นเอง (เคยเขียนไปแล้วในตอน Google I/O 2025)
สำหรับคนที่สนใจเรื่อง Scaling Laws แนะนำให้ดูคลิปอธิบายของช่อง Welch Labs ทำไว้ละเอียดดีมากๆ (โดยเฉพาะเรื่อง cross entropy loss ที่ไม่ได้เขียนถึงในโพสต์นี้ เพราะละเอียดเกินไป) และทำคลิป visual สวยมากด้วย