ถ้าถามว่าอะไรคือสิ่งที่ทำให้ผมตื่นเต้นที่สุดกับวงการ AI ในช่วงครึ่งหลังของปีนี้ คำตอบง่ายมากคือกระแสของสถาปัตยกรรมใหม่ Mamba ที่กำลังเริ่มมาแรง และอาจขึ้นมาท้าทาย Transformer ได้ด้วย
จุดอ่อนของ Transformer
โมเดลภาษาที่เราใช้กันอยู่ในทุกวันนี้ ล้วนพัฒนามาจากสถาปัตยกรรมโมเดล Transformer ที่คิดขึ้นโดยกูเกิลในปี 2017 (ตัว T ในคำว่า GPT มาจากคำว่า Transformer) จุดเด่นของโมเดลตระกูล Transformer คือกลไกที่เรียกว่า self-attention (ตามชื่อเปเปอร์ Attention Is All You Need) ที่ทำให้อ่านคำ (token) แบบย้อนหลังได้ ช่วยให้คุณภาพของผลลัพธ์ที่โมเดลพยากรณ์คำออกมาดีกว่าโมเดลรุ่นก่อนๆ หน้าอย่างก้าวกระโดด
อย่างไรก็ตาม ข้อเสียของ Transformer คือวิธีการประมวลผลของ self-attention มันกินพลังเยอะ ต้องจับคู่ token ทั้งหมดมาเทียบกัน ถ้าพูดเป็นภาษาคณิตศาสตร์คือเป็นสมการยกกำลังสอง (quadratic) หรือถ้าเรียกเป็น Big O คือ O(N^2) ยิ่งถ้าต้องเจอกับ input sequence ขนาดยาวมากๆ ก็ยิ่งสิ้นเปลืองพลังประมวลผลมากสุดๆ ไปเลย
หลังการเกิดขึ้นของ Transformer จึงมีเทคนิคต่างๆ พยายามแก้จุดอ่อนเรื่อง quadratic ของมัน (ซึ่งจะไม่กล่าวถึงในที่นี้) ในอีกทางก็มีคนพยายามคิดสถาปัตยกรรมโมเดลใหม่ๆ มาแข่งกับ Transformer ซึ่งผ่านมาหลายปี ดูเหมือนว่า Mamba จะเข้าเค้ามากที่สุดแล้ว
State Space Model (SSM)
สถาปัตยกรรม Mamba ถูกเสนอขึ้นมาในเปเปอร์ ปี 2023 โดยนักวิจัย 2 คนคือ Albert Gu (CMU) และ Tri Dao (Princeton) แต่แนวคิดของมันพัฒนามาก่อนหน้านั้นอย่างยาวนาน เพราะมันอิงอยู่บนโมเดลคณิตศาสตร์ที่เรียกว่า State Space Model (SSM) ที่ใช้กันมานานแล้วในวงการวิศวกรรมควบคุม-ประมวลผลสัญญาณ
อธิบายแบบเข้าใจง่ายที่สุดเท่าที่ทำได้ State Space Model (SSM) เป็นวิธีการเทียบสถานะ (state representation) จากโลกจริงมาเป็นโมเดลคณิตศาสตร์แบบหนึ่ง หลักคิดสำคัญของมันคือ วัตถุใดๆ จะเปลี่ยนแปลงจากปัจจัย 2 อย่างหลักคือ ตัวมันเปลี่ยนสถานะด้วยตัวเอง และ มีอินพุตภายนอกเข้ามาเอี่ยวด้วย เมื่อเราได้ข้อมูลทั้ง 2 อย่างแล้ว เราจะสามารถ “ทำนาย” สถานะขั้นถัดไปของวัตถุนั้นได้
เห็นคำว่า “ทำนาย” ไหมครับ นี่แหละเราจะเอา State Space Model มาใช้ทำนายคำ (token) ของโมเดลภาษากัน
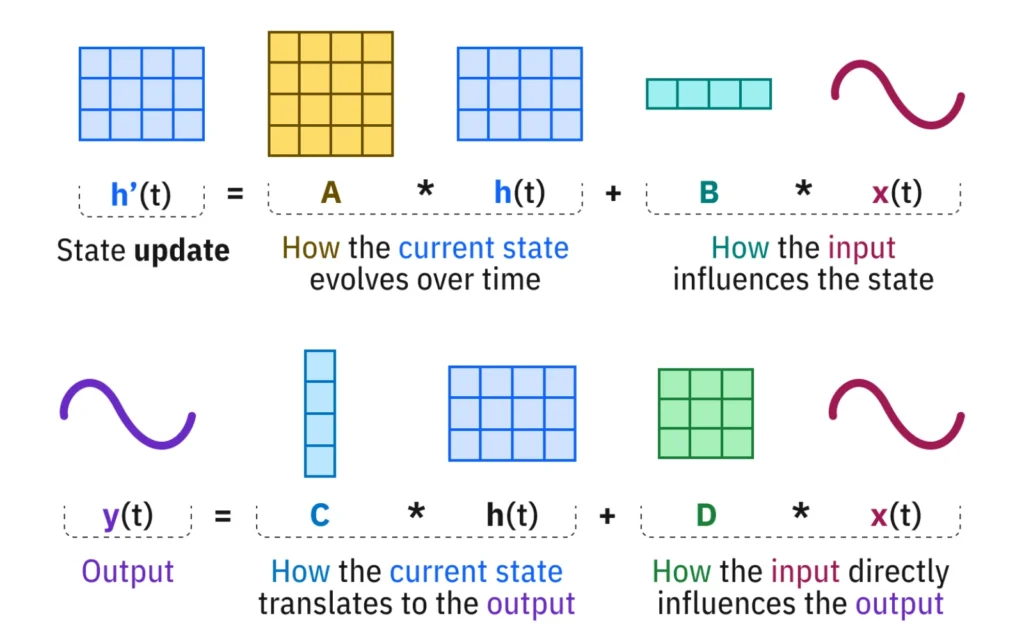
แนวคิดหลักของ State Space Model – ภาพจาก IBM
State Space Model ถูกใช้ในวงการวิศวกรรมควบคุม วิศวกรรมไฟฟ้า มานานมากแล้ว เดิมทีมันถูกคิดขึ้นมาสำหรับประมวลผลสัญญาณที่มีความต่อเนื่อง (continuous sequence) เช่น คลื่นไฟฟ้า สภาพอากาศ
แต่ภายหลังก็มีคนพยายามนำมันมาใช้กับข้อมูลที่ไม่ต่อเนื่อง (discrete sequence) อย่างโมเดลภาษาที่ทำนายคำออกมาทีละคำ โดยใช้วิธีแปลงอินพุตแบบ discrete เป็น continuous แล้วเอาไปเข้าโมเดล SSM พอได้เอาท์พุตออกมาก็แปลงกลับเป็น discrete ใหม่ วิธีการนี้เรียกว่า Discrete SSM
การทำงานของ Discrete SSM คล้ายกับแนวทาง recurrent neural networks (RNNs) ที่เคยนิยมในวงการ AI ยุคก่อนหน้า Transformer ซึ่งมีจุดเด่นตรงที่มันประมวลผลตอนรัน (inference) แบบเชิงเส้น (linear) ได้ออกมาเป็น O(N logN) ที่ใช้พลังประมวลผลน้อยกว่า Transformer มาก
อย่างไรก็ตาม Discrete SSM ยังมีข้อจำกัดเรื่องประสิทธิภาพหลายอย่างที่ผลลัพธ์ออกมาสู้ Transformer ไม่ได้ ในวงการวิจัยจึงพยายามพัฒนา Discrete SSM ต่อ
Structure State Space Sequence Model (S4)
ในปี 2021 Albert Gu ผู้คิดค้นโมเดล Mamba นี่ล่ะ ได้เสนอแนวทางพัฒนาที่เรียกว่า Structure State Space Sequence Model (หรือย่อว่า S4 เพราะมันมี S สี่ตัว) ถือเป็นเวอร์ชันต้นแบบที่จะกลายเป็น Mamba ในภายหลัง
ข้อดีของโมเดลแบบ RNN (ซึ่งครอบคลุมถึง SSM) คือประมวลผลแบบเชิงเส้น ประมวลผลตามลำดับ (linear) ทำให้ไม่สิ้นเปลืองพลังประมวลผลตอนรัน แต่มันก็กลายเป็นข้อเสียในตอนเทรนโมเดล เพราะมันต้องทำตามลำดับ ประมวลผลแบบขนานไม่ได้ กลายเป็นว่าเทรนช้ามาก
สถาปัตยกรรม S4 ของ Albert Gu แก้ปัญหาความช้าในการเทรนโมเดลของ SSM โดยนำแนวคิดจากสายตรงข้ามกับ RNN คือ convolutional neural networks (CNNs ซึ่งนิยมใช้กันในสายประมวลผลภาพ computer vision) มาใช้ตอนเทรน นำเทคนิคที่เรียกว่า kernel มาแปลงข้อมูลตอนเทรนให้ทำงานได้เร็วขึ้น
นอกจากนี้ S4 ยังแก้ปัญหาอีกอย่างของ SSM คือการประมวลผลข้อมูลที่ยาวๆ แล้วความเชื่อมโยงระหว่างข้อมูลส่วนต้นกับส่วนปลายมันจะหายไป (ในวงการ AI เรียกปัญหานี้ว่า long-term memory) ผลลัพธ์ที่ได้ออกมาไม่แม่น แนวทางแก้ปัญหานี้เรียกว่า HiPPO (ย่อมาจาก High-order Polynomial Projection Operators) ซึ่งอธิบายสั้นๆ ตรงนี้พอว่าเป็นการทำ structuring หรือกำหนดข้อมูลในเมทริกซ์ที่นำมาประมวลผล (เป็นเหตุผลว่าทำไมชื่อของโมเดล S4 มีคำว่า Structure เพิ่มเข้ามา)
Transformers power most advances in LLMs, but its core attention layer can’t scale to long context.
With @_albertgu, we’re releasing Mamba, an SSM architecture that matches/beats Transformers in language modeling, yet with linear scaling and 5x higher inference throughput.
1/ https://t.co/xnWtFVFthS pic.twitter.com/7gdXw1qP2H— Tri Dao (@tri_dao) December 4, 2023
Mamba
สถาปัตยกรรม S4 สามารถแก้ปัญหาความเร็วในการเทรน และความสามารถในการประมวลผลข้อความยาวๆ ได้แล้ว หลังจากนั้น ทีมของ Albert Gu ยังพัฒนาโมเดล S4 ต่อในแง่มุมอื่นเพื่อให้ทัดเทียมกับ Transformer จนออกมาเป็น Mamba ในปี 2023
ในวงการ LLM พยากรณ์คำ มีบางครั้งที่เราต้องการให้โมเดลคัดลอกอินพุตเฉพาะแค่บางคำออกมาเป็นเอาท์พุต (ตัดบางส่วนออก แต่ต้องตอบแบบเรียงตามลำดับเดิม) ซึ่งกลไก attention ของ Transformer สามารถทำได้สบาย แต่วิธีทำงานของ SSM ที่รับอินพุตเป็นเชิงเส้นไม่สามารถทำได้
Gu แก้ปัญหานี้โดยกลไกที่เรียกว่า Selective Scan ปรับวิธีการบีบอัดข้อมูลอินพุตให้กรองข้อมูลบางอย่างออกได้ ส่งผลให้ความสามารถเรื่องนี้เทียบเท่ากับ Transformer โดยประสิทธิภาพดีกว่า
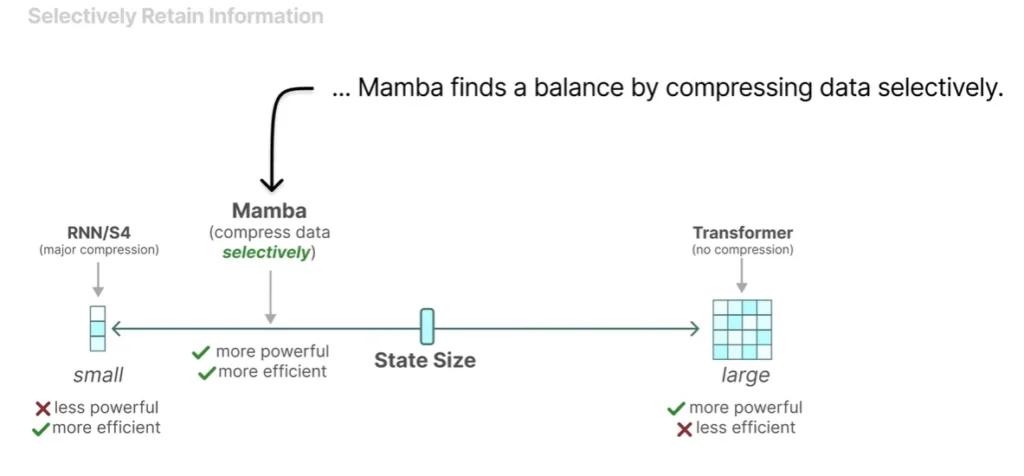
Selective Scan – ภาพจาก Maarten Grootendorst
การที่โมเดล S4 เพิ่มท่า Selective Scan เข้ามา ทำให้ตอนนี้ชื่อมันยาวขึ้นเป็น S6 ซึ่งชักจะยาวเกินไปแล้วนะ
Albert Gu เลยตั้งชื่อใหม่ให้มันว่า Mamba ตามสายพันธุ์งูพิษพันธุ์ดุ ด้วยเหตุผลว่าการออกเสียง S เยอะๆ 6 ตัวเหมือนกับเสียงงูกำลังขู่ บวกกับ Mamba รวดเร็วและดุร้าย (fast & deadly) เหมือนกับงูจริงๆ (มันเป็นแบบนี้นี่เอง)
Why “Mamba”?
– It’s fast: based on a (i) simple recurrence with linear scaling in sequence length, and (ii) hardware-aware design and implementation
– It’s deadly — to sequence modeling problems
– Its core mechanism is the latest evolution of S4 models… SSSS
8/— Albert Gu (@_albertgu) December 4, 2023
นอกจากเรื่อง Selective Scan แล้ว Mamba ยังมีของใหม่เพิ่มมาจาก S4 อีกอย่าง คือ การออกแบบให้คำนวณบนฮาร์ดแวร์ (GPU) ของจริงได้มีประสิทธิภาพมากขึ้นด้วย (ไม่ได้เป็นแค่โมเดลคณิตศาสตร์) โดยอาศัยข้อจำกัดของ GPU ที่มี SRAM (เร็ว) และ DRAM (ช้ากว่า) แล้วต้องโอนถ่ายข้อมูลไปมาระหว่างแรม 2 แบบนี้ การโอนถ่ายถือเป็นคอขวดสำคัญของ GPU (compute เร็วกว่า data transfer มาก) สถาปัตยกรรม Mamba จึงเลือกเก็บงานบางอย่างทำบน SRAM เท่านั้น และงานบางอย่างทำบน DRAM เท่านั้น ไม่ข้ามกลับไปกลับมาบ่อยๆ ผลลัพธ์สุดท้ายจึงกลายเป็นว่า Mamba ตอนไปรันบน GPU จริงๆ จึงเร็วขึ้นมาก
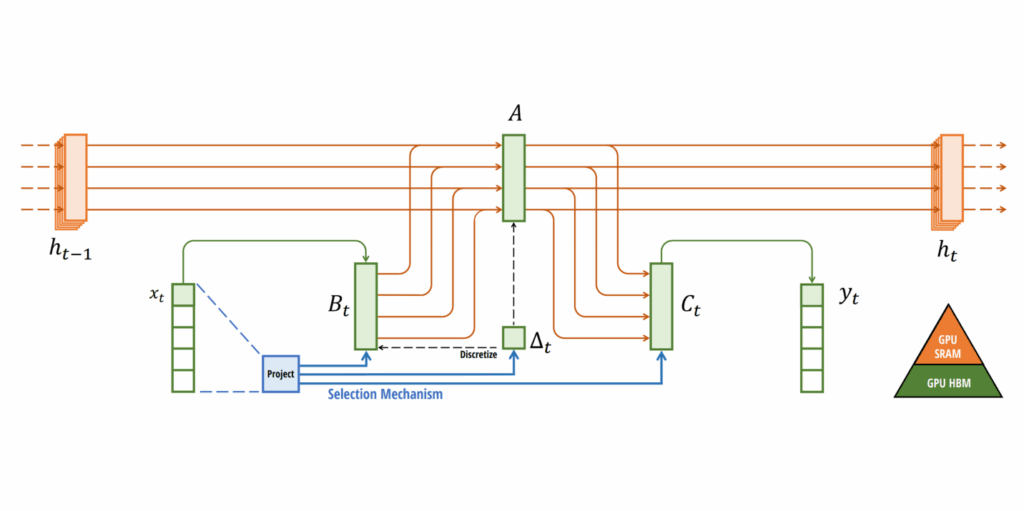
ภาพการออกแบบการทำงานบน SRAM (สีส้ม) และ DRAM (สีเขียว) จากเปเปอร์ Mamba
สถาปัตยกรรม Mamba ที่แก้ปัญหาต่างๆ ของ SSM ไปมากแล้ว สามารถทำผลลัพธ์ออกมาได้ดีไม่แพ้ Transformer เลย (แม้ยังมีจุดอ่อนบางอย่างเหลืออยู่บ้าง) มันจึงส่งผลสะเทือนต่อวงการ LLM เป็นอย่างมาก ทำให้ Mamba กลายเป็นจุดสนใจและถูกนำไปพัฒนาต่อยอดอีกเยอะ
ทีมของ Gu และ Dao ยังออก เปเปอร์ใหม่ในปี 2024 พัฒนาเป็นสถาปัตยกรรม Mamba-2 ที่ทำงานได้เร็วขึ้นอีกขั้น ด้วยเทคนิคใหม่ที่เรียกว่า state space duality (SSD) นำแนวคิดเรื่อง multi-head attention ของ Transformer มาใช้งาน สามารถประมวลผลแบบขนานได้เร็วขึ้น
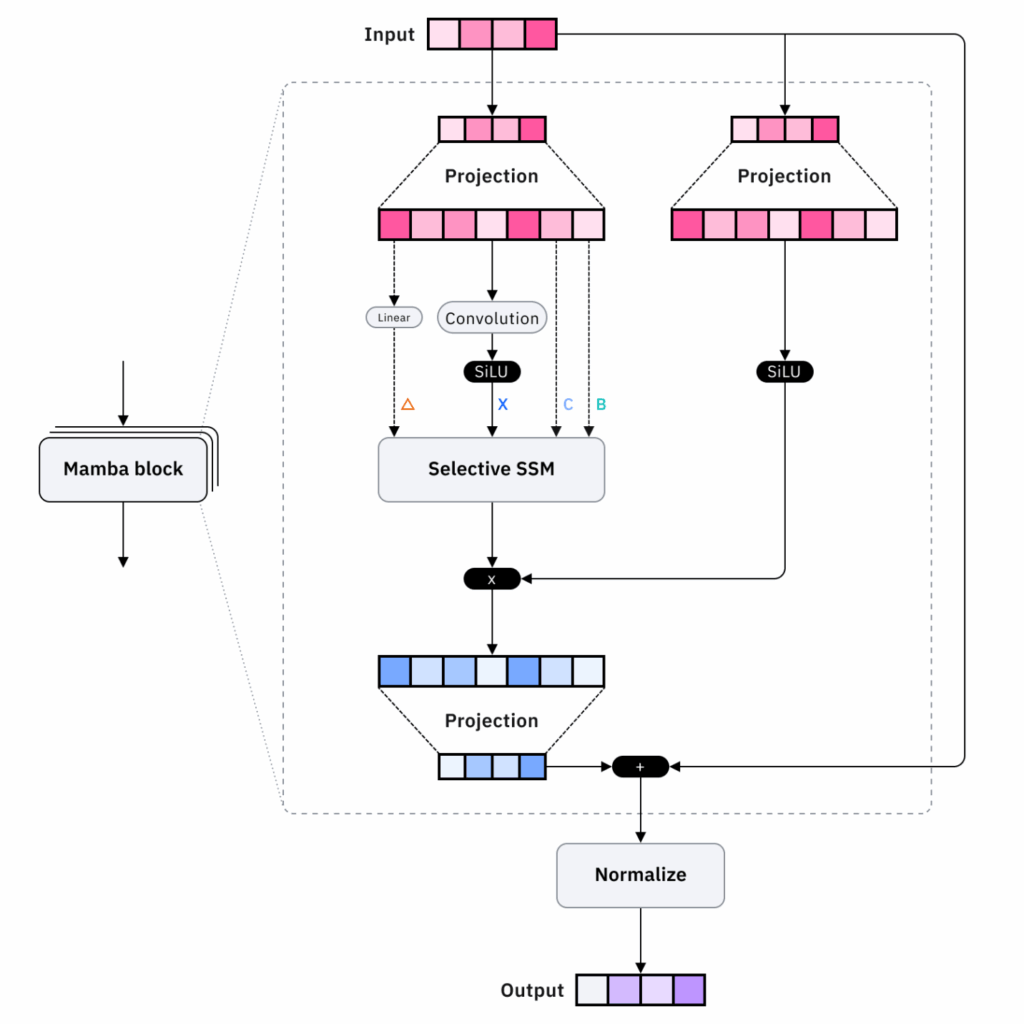
สถาปัตยกรรม Mamba 2 ร่างล่าสุด – ภาพจาก IBM
Mamba vs Transformer
หลังจากโมเดลตระกูล SSM/Mamba พัฒนาอย่างก้าวกระโดดในช่วงหลัง ทำผลงานได้ดีไม่แพ้ Transformer ก็เริ่มมีคำถามว่าตกลงแล้ว Mamba จะมาโค่น Transformer หรือเปล่า
คำตอบดูเหมือนจะไปทางตรงข้ามแทน นั่นคือ มันกำลังหลอมรวมเข้าหากันเป็นโมเดลแบบไฮบริด ที่มีทั้ง Mamba และ Transformer เพื่อชดเชยจุดอ่อนซึ่งกันและกัน โดย Transformer ยังให้ผลลัพธ์เหนือกว่า ในขณะที่ Mamba ทำงานเร็วกว่า
ใครที่เคยศึกษา Transformer คงพอทราบว่ากลไก Attention มันทำงานเป็น “บล็อค” แล้วนำมาต่อๆ กันเป็นหลาย “เลเยอร์” เพื่อเพิ่มขีดความสามารถของการประมวลผลคำให้เยอะขึ้น ด้วยโครงสร้างแบบนี้จึงมีคนเกิดไอเดียเอาบล็อค Mamba มาต่อกับบล็อค Attention นั่นเอง
สถาปัตยกรรมไฮบริด Mamba + Attention ของ IBM Granite 4.0
เท่าที่หาข้อมูลได้ มีอยู่ 2 ค่ายใหญ่ๆ ที่พัฒนาโมเดลตามแนวทางไฮบริด คือ
- Jamba จากสตาร์ตอัพชื่อ AI24 ของอิสราเอล (น่าจะล้อจากคำว่า Mumbo Jumbo มาเป็น Mamba Jamba) โดยค่ายนี้ได้รับการสนับสนุนจาก Andrew Ng จนมี คอร์สสอน Jamba บน DeepLearning.ai ด้วย
- Bamba จากยักษ์สีฟ้า IBM ที่ร่วมกับ Dao และ Gu พัฒนา Mamba ต่อแบบไฮบริด ร่างล่าสุดคือถูกนำไปใช้งานใน โมเดลเชิงพาณิชย์ Granite 4.0 ของ IBM แล้วด้วย

สถาปัตยกรรมไฮบริดของ Jamba

โพสต์เชียร์จาก Andrew Ng
New short course: Build Long-Context AI Apps with Jamba. Learn about state space models (SSMs), which have emerged as an alternative to transformers! Specifically, Jamba is a hybrid transformer-Mamba architecture that combines strengths of the transformer with ideas from SSMs.… pic.twitter.com/JqtPVsxane
— Andrew Ng (@AndrewYNg) January 8, 2025
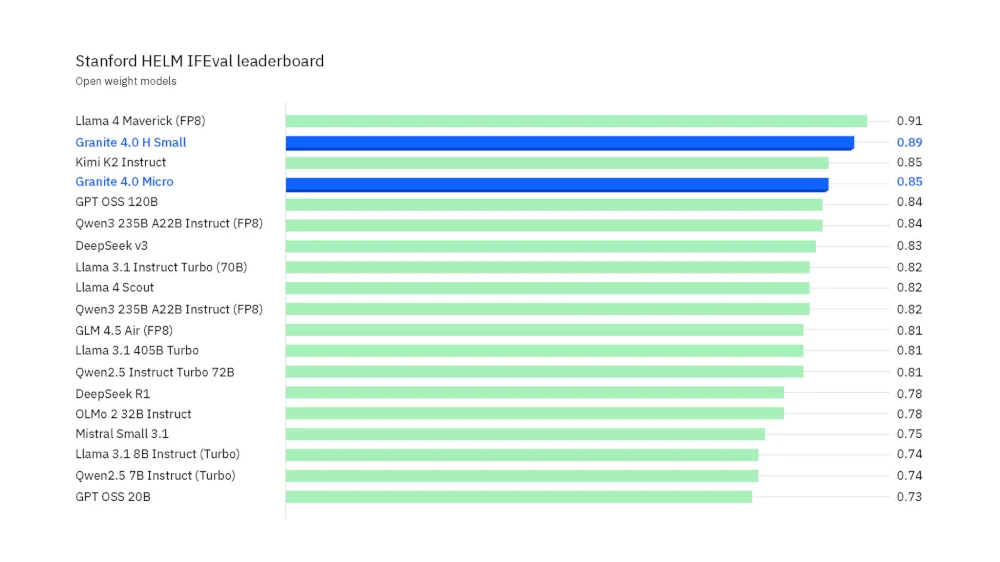
เท่าที่ผมหาข้อมูลล่าสุด ณ เวลาที่เขียนโพสต์นี้ โมเดลไฮบริดอย่าง Granite 4.0 ทำงานได้เร็วจริง กินแรมน้อยกว่าโมเดลตระกูล Transformer มาก ส่วนประสิทธิภาพในภาพรวมนั้น IBM ยังปล่อยมาเฉพาะ Granite-4.0-Small ตัวเล็ก (32B) ที่เอาชนะโมเดลสาย open weight ตัวใหญ่กว่าอย่าง Llama 4 Maverick (402B), GPT OSS (120B) ได้แล้ว ก็ต้องรอดูกันต่อไปว่าหาก Granite-4.0 ตัวใหญ่กว่านี้ออกมา ผลลัพธ์มันจะสามารถไปเทียบชั้นโมเดลรุ่นท็อปๆ อย่าง GPT-5, Claude Sonnet 4.5, Gemini 2.5 Pro ได้ประมาณไหนกัน
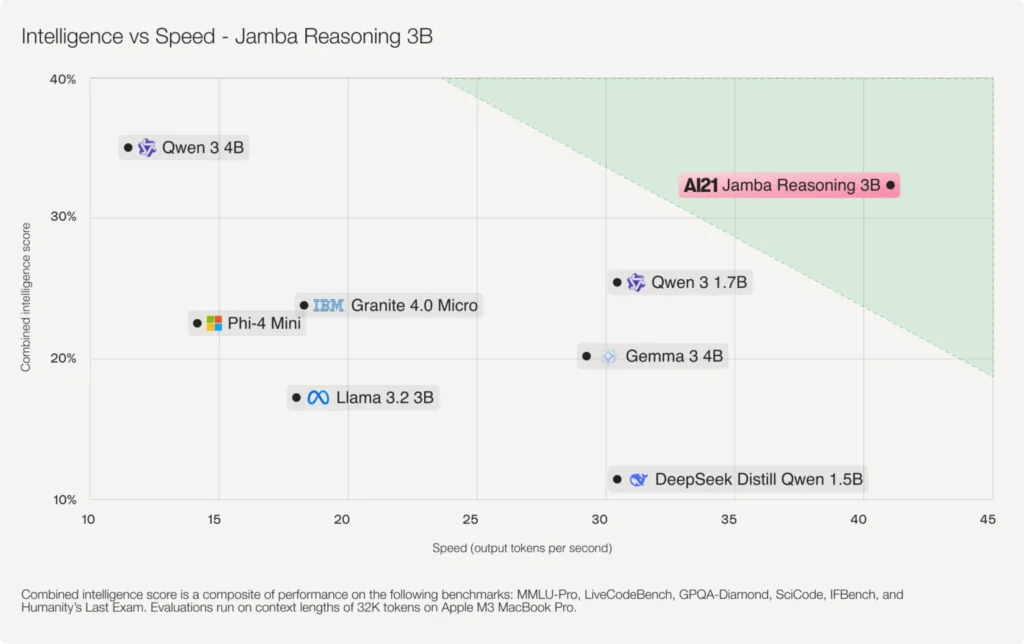
ฝั่งของบ้าน Jamba เพิ่งออก Jamba Reasoning เพิ่มฟีเจอร์คิดเป็นเหตุเป็นผลออกมา โดยยังเป็นโมเดลไซส์เล็ก 3B เน้นทำงานบนพีซีหรือสมาร์ทโฟน แต่ก็คุยว่าความฉลาดเอาชนะคู่แข่งระดับเดียวกัน เช่น Qwen 3 1.7B และ Gemma 3 4B ได้แล้ว เรื่องความเร็วนั้นไม่ต้องพูดถึงอยู่แล้วเพราะมันชนะกันที่สถาปัตยกรรม
สำหรับผู้สนใจศึกษาเรื่อง Mamba เพิ่มเติม แนะนำให้อ่าน
- บทความของ IBM อธิบายพัฒนาการของ Mamba
- คลิปของ Maarten Grootendorst ทำภาพอธิบาย Mamba ได้เข้าใจง่ายมากสุดๆ คุ้มค่าเวลา 24 นาทีแน่นอน