
เวลาได้ไปสอนเรื่อง AI ผมมักจะพูดถึง “ข้อจำกัด” ของโมเดลในปัจจุบันก่อนเพื่อให้คนฟังรู้ว่ามันทำอะไรได้และไม่ได้กันแน่
วิธีอธิบายของผมคือบอกว่า LLM มันคือ “เครื่องพ่นคำถัดไป” แต่กระบวนการข้างในนั้น ผมก็ไม่สามารถหาวิธีมาอธิบายมันได้ดีนัก เหมือนเป็น black box กล่องดำมหัศจรรย์มากกว่า
จนกระทั่งมาเจอคลิปของช่องนี้ 3Blue1Brown ซึ่งเขาดังมานานแล้ว (แต่ดันเพิ่งรู้จัก) ที่ทำ visualization ของโมเดลตระกูล Transformer ที่เราใช้กันในปัจจุบัน (ตัว “T” ใน GPT) ออกมาเป็นภาพให้เห็นชัดๆ ทำออกมาได้ดีมาก งานเกรดระดับว่าใช้เป็นสื่อการสอนในมหาวิทยาลัยได้เลย
เลยเอามาแนะนำกันว่า ใครที่สนใจลงลึกว่า โมเดล AI ตระกูล Transformer (ในคลิปใช้ตัวอย่างเป็น GPT-3) จริงๆ แล้วมันทำงานอย่างไร คลิปมี 3 ตอนไล่ไปตั้งแต่
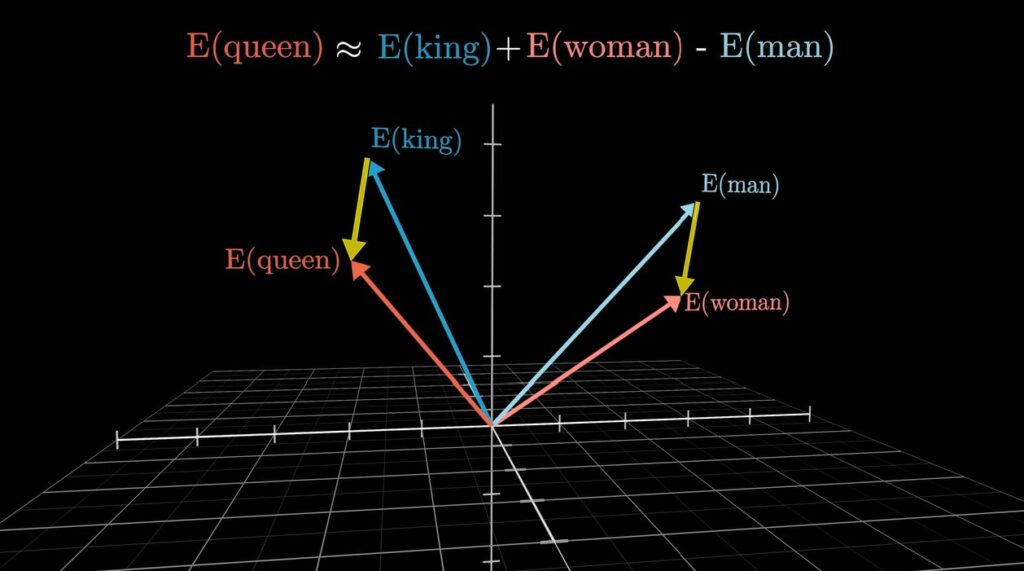
- Embedding หรือการนำ “คำ” มาทำเป็น vector วัดหาความเชื่อมโยงกัน
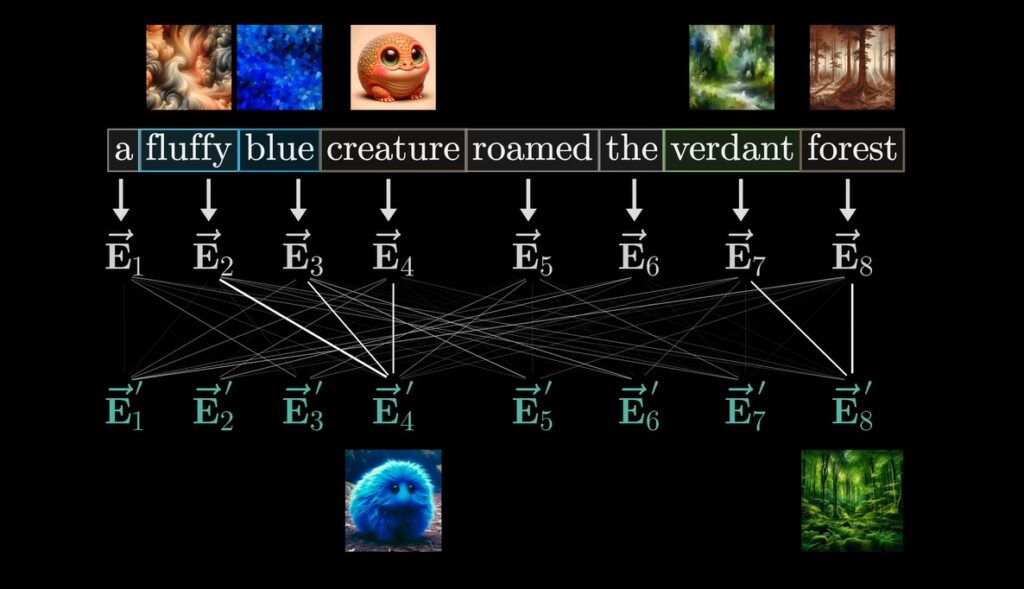
- Attention ระบบการให้คะแนนความเชื่อมโยงระหว่างคำ ซึ่งเป็นเคล็ดลับสำคัญที่เกิดโมเดล Transformer ที่ทรงประสิทธิภาพ
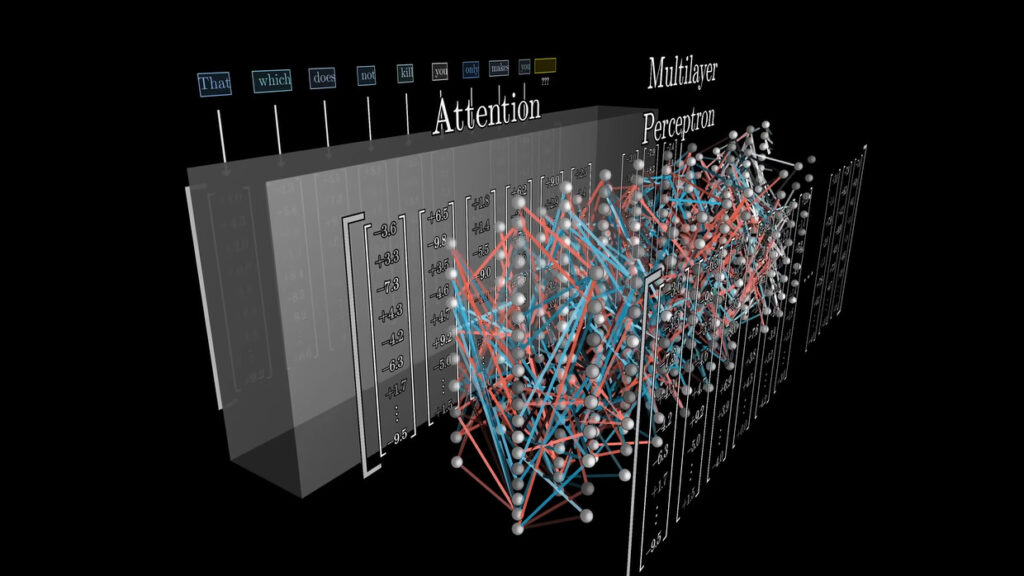
- Multilayer Perceptron คือการคำนวณเมทริกซ์กันเป็นชั้นๆ จำนวนมาก อันนี้แหละคือคำตอบว่าเราซื้อ GPU กันแพงๆ ไปทำไม คำตอบคือเอาไปคูณเมทริกซ์นี่เอง
คลิปรวมในซีรีส์นี้มีทั้งหมด 7 ตอน ไล่ย้อนไปตั้งแต่พื้นฐานเรื่องการทำ Neural Network, Gradient Descent, Backpropagation (ซึ่งเป็นเรื่อง math สำหรับงานสาย AI ตามที่เคยโพสต์ไว้คราวก่อน)
ใครที่สนใจเรียนรู้เรื่อง AI แบบลงลึกหน่อย ดูครบ 7 ตอนน่าจะเข้าใจกระบวนการทำงานของมันเพิ่มขึ้นอีกมาก แนะนำจริงๆ