อ่านเปเปอร์เรื่อง AI แล้วพบคำศัพท์ว่า Embedding เลยไปอ่านข้อมูลเพิ่ม เจอคอร์สของ Google Machine Learning สรุปไว้ค่อนข้างดี (มีคลิปด้วย)
พื้นฐานของการทำ prediction นั้นเป็นการคำนวณทางคณิตศาสตร์ โดยหาแพทเทิร์นความสัมพันธ์ของข้อมูลชนิกเวกเตอร์ ซึ่งการหาความสัมพันธ์ให้ได้ดีและแม่นยำ เวกเตอร์ต้องมีการเกาะกลุ่มกัน (dense vector)
แต่ข้อมูลที่เรานำเข้ามาทำนาย มักเป็นเวกเตอร์ที่กระจัดกระจาย (sparse vector) ซึ่งหาความสัมพันธ์ได้ยาก และหากข้อมูลมีขนาดใหญ่ ยิ่งสิ้นเปลืองพลังประมวลผล ในวงการ machine learning จึงมีเทคนิค “ตบ” ข้อมูลให้จำกัดวงแคบลง เทคนิคอันนี้ล่ะเรียกว่า embedding
ฟังแล้วเข้าใจยาก ดูตัวอย่างดีกว่า
หากเราเป็น Netflix และต้องการพยากรณ์หนังที่ผู้ใช้ของเราชอบ เราจะมีข้อมูลขนาดใหญ่มากคือ ตารางที่ประกอบด้วยผู้ใช้แต่ละคน x หนังทั้งหมดที่ผู้ใช้แต่ละคนดู หากเรามีผู้ใช้ 1,000,000 คน x หนัง 500,000 เรื่อง เวลาจับคูณความเป็นไปได้แล้ว ตารางมันจะขนาดใหญ่มหาศาล

การเอาข้อมูลดิบของหนัง 500,000 เรื่องมาคำนวณไปทีละชุด หาความสัมพันธ์ไปเรื่อยๆ มันเยอะเกินไป
เรามาหาความสัมพันธ์ของหนังแต่ละเรื่องกันเองก่อนว่ามันมีความคล้ายกันหรือเปล่า ตรงนี้คือการสร้างมิติความสัมพันธ์ (dimension space) เพิ่มเข้ามาอีกก้อน ซึ่งจำนวนมิติจะเป็น 1, 2, 3 ก็ได้แล้วแต่กรณี แต่เพื่อความง่ายก็ควรใช้มิติน้อยๆ (low-dimension)
ตัวอย่างความสัมพันธ์ของหนังแบบ 1 มิติ หนังที่อยู่ใกล้กันแปลว่าคล้ายกัน

ตัวอย่างความสัมพันธ์ของหนังแบบ 2 มิติ เพิ่มแกนของอายุผู้ชม (เด็ก-ผู้ใหญ่) และสไตล์ของหนัง (แมส-อาร์ท) เข้ามา
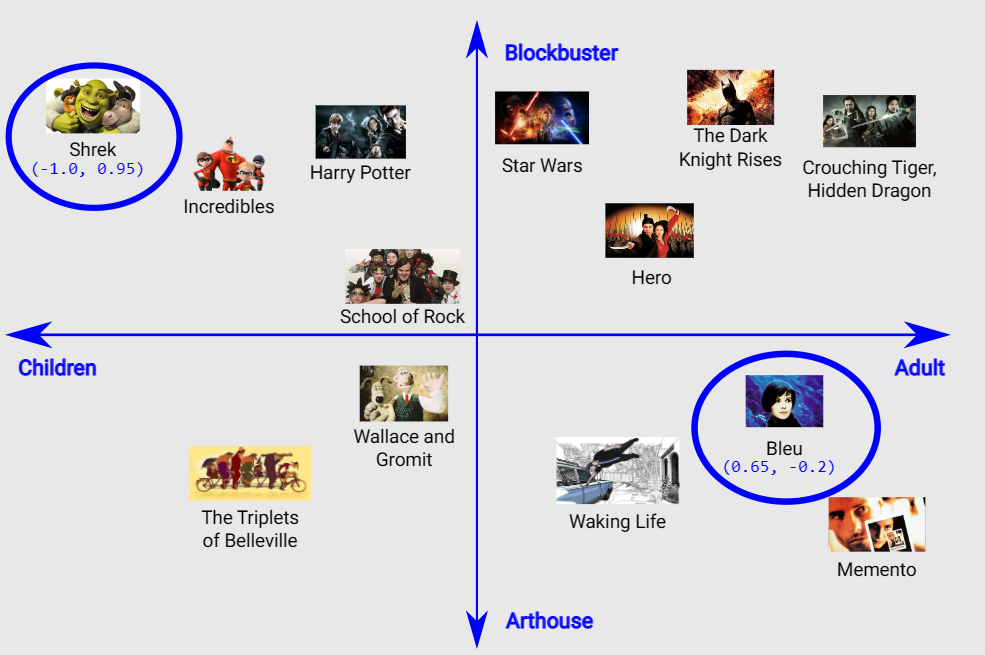
การสร้างมิติความสัมพันธ์แบบนี้ (ที่เรียกว่า embedding space) จำเป็นต้องเพิ่มข้อมูลภายนอก (นอกจากอินพุตหลักของ prediction) ซึ่งจะใช้วิธีใดก็แล้วแต่ อย่างเคสเรื่องรูปแบบของหนัง เราอาจใช้เรตอายุของหนัง + การประเมินเองว่าเป็นหนังแมส/อาร์ท แล้วพล็อตจุดในกราฟ 2D เองได้ หรือถ้าเป็นข้อมูลรูปแบบที่ใช้บ่อยๆ ก็มีตัวช่วย เช่น Word2Vec
สิ่งที่เราต้องการจากกราฟข้างบนคือ ข้อมูลตัวเลขว่าหนังเรื่องนั้นมีพิกัดเท่าไร (เช่น Shrek คือ -1.0, 0.95) เพื่อนำตัวเลขนี้ไปคำนวณตอนเทรนโมเดล มันจะกลายเป็นตารางข้อมูลที่เรียกว่า embedding tables
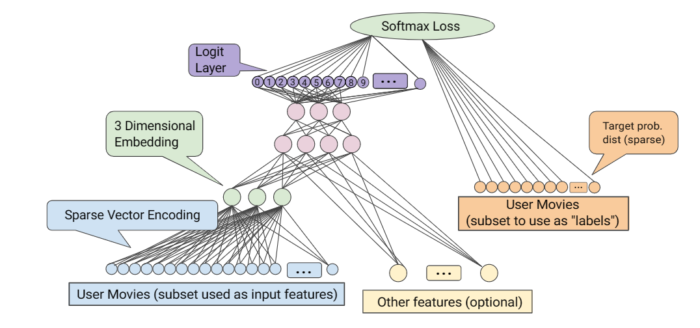
ในสถาปัตยกรรม deep learning network (DNN) ตามภาพด้านล่าง เราจะเห็นการเพิ่มชั้นสีเขียว (embedding) เข้ามาคั่นกลางระหว่างรายการหนังทั้งหมด (สีฟ้า) เพื่อ “คัดกรอง” หาความสัมพันธ์ของหนังก่อนไป
การที่ชั้นของ embedding มีจำนวนมิติไม่มากนัก (1-3 มิติ) ความเป็นไปได้ของการคำนวณจึงลดลงมากในโมเดลชั้นถัดไป
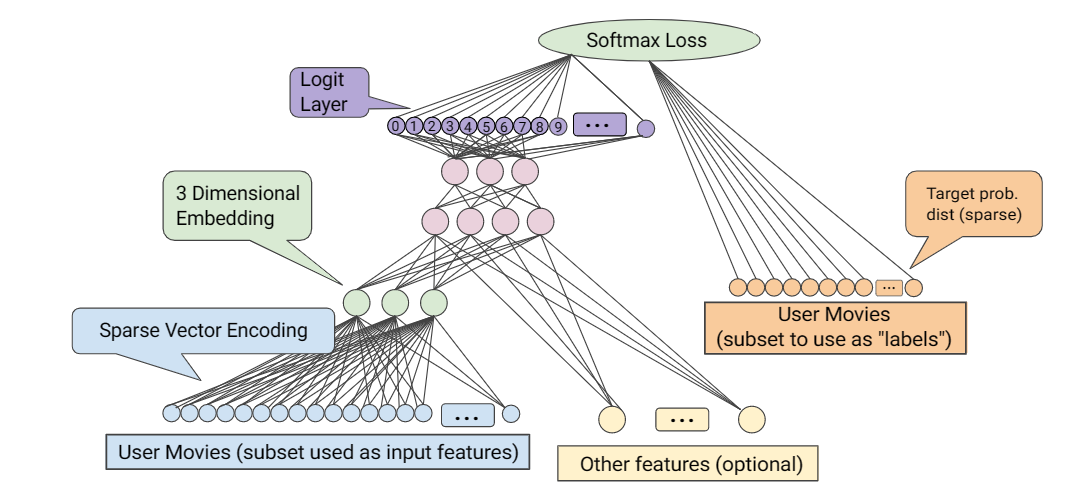
เทคนิค Embedding ถือเป็นมาตรฐานสำหรับโมเดลแบบ Deep Learning Recommendation Models (DLRM) ที่ใช้พยากรณ์เรื่องต่างๆ ไปแล้ว โดยมันจะอยู่ในชั้นแรก (first layer) ที่ใช้กรองข้อมูลในโมเดลก่อน
ตัวตาราง embedding tables มีจำนวนมิติน้อยแน่นอน แต่ในแต่ละมิติ อาจมีขนาดใหญ่มากๆ ได้ การค้นหาข้อมูลในตาราง (lookup) อาจต้องโหลดตารางขนาดใหญ่เข้ามาในหน่วยความจำ ซึ่งในทางปฏิบัติก็มีเทคนิคจำพวก sharding แบ่งส่วนตารางเพื่อลดขนาดของปัญหาลงได้เช่นกัน ซึ่งกูเกิลก็พัฒนาฮาร์ดแวร์ที่เรียกว่า SparseCore เข้ามาช่วยในเรื่องนี้ (เปเปอร์)